标准函数和内部函数在数值精确度和性能上的表现是不同的。标准函数支持大部分的数学运算。但是,许多等效的内部函数能够使用较少的指令、改进的性能和更低的数值精确度,实现相同的功能。
就比如这个程序:
#include "freshman.h"
#include <stdio.h>
#include <stdlib.h>
#include <cmath>
/**
* This example demonstrates the relative performance and accuracy of CUDA
* standard and intrinsic functions.
*
* The computational kernel of this example is the iterative calculation of a
* value squared. This computation is done on the host, on the device with a
* standard function, and on the device with an intrinsic function. The results
* from all three are compared for numerical accuracy (with the host as the
* baseline), and the performance of standard and intrinsic functions is also
* compared.
**/
/**
* Perform iters power operations using the standard powf function.
**/
__global__ void standard_kernel(float a, float* out, int iters)
{
int i;
int tid = (blockDim.x * blockIdx.x) + threadIdx.x;
if (tid == 0)
{
float tmp;
for (i = 0; i < iters; i++)
{
tmp = powf(a, 2.0f);
}
*out = tmp;
}
}
/**
* Perform iters power operations using the intrinsic __powf function.
**/
__global__ void intrinsic_kernel(float a, float* out, int iters)
{
int i;
int tid = (blockDim.x * blockIdx.x) + threadIdx.x;
if (tid == 0)
{
float tmp;
for (i = 0; i < iters; i++)
{
tmp = __powf(a, 2.0f);
}
*out = tmp;
}
}
int main(int argc, char** argv)
{
int i;
int runs = 30;
int iters = 1000;
float* d_standard_out, h_standard_out;
CHECK(cudaMalloc((void**)&d_standard_out, sizeof(float)));
float* d_intrinsic_out, h_intrinsic_out;
CHECK(cudaMalloc((void**)&d_intrinsic_out, sizeof(float)));
float input_value = 8181.25;
double mean_intrinsic_time = 0.0;
double mean_standard_time = 0.0;
for (i = 0; i < runs; i++)
{
double start_standard = cpuSecond();
standard_kernel << <1, 32 >> > (input_value, d_standard_out, iters);
CHECK(cudaDeviceSynchronize());
mean_standard_time += cpuSecond() - start_standard;
double start_intrinsic = cpuSecond();
intrinsic_kernel << <1, 32 >> > (input_value, d_intrinsic_out, iters);
CHECK(cudaDeviceSynchronize());
mean_intrinsic_time += cpuSecond() - start_intrinsic;
}
CHECK(cudaMemcpy(&h_standard_out, d_standard_out, sizeof(float),
cudaMemcpyDeviceToHost));
CHECK(cudaMemcpy(&h_intrinsic_out, d_intrinsic_out, sizeof(float),
cudaMemcpyDeviceToHost));
float host_value = powf(input_value, 2.0f);
printf("Host calculated\t\t\t%f\n", host_value);
printf("Standard Device calculated\t%f\n", h_standard_out);
printf("Intrinsic Device calculated\t%f\n", h_intrinsic_out);
printf("Host equals Standard?\t\t%s diff=%e\n",
host_value == h_standard_out ? "Yes" : "No",
fabs(host_value - h_standard_out));
printf("Host equals Intrinsic?\t\t%s diff=%e\n",
host_value == h_intrinsic_out ? "Yes" : "No",
fabs(host_value - h_intrinsic_out));
printf("Standard equals Intrinsic?\t%s diff=%e\n",
h_standard_out == h_intrinsic_out ? "Yes" : "No",
fabs(h_standard_out - h_intrinsic_out));
printf("\n");
printf("Mean execution time for standard function powf: %f s\n",
mean_standard_time);
printf("Mean execution time for intrinsic function __powf: %f s\n",
mean_intrinsic_time);
return 0;
}结果如下图所示:
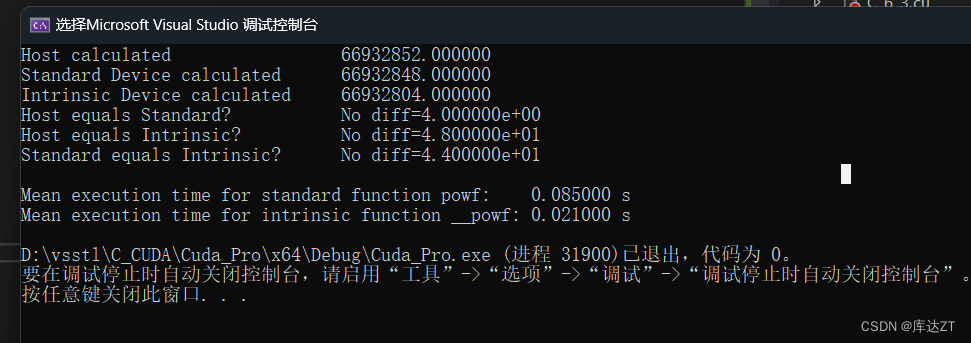
可以看到对于标准函数powf或是内部函数__powf,与主机中所计算的pow都是不同的,但是标准函数的误差明显更小,但是内部函数的计算更快。
即使使用数值稳定的CUDA函数,GPU上的运算结果仍与传统的只在CPU上运行的应用结果不同。由于主机和设备上的浮点运算都存在固有的不精确性,有时很难指出一个输 出结果与另一个输出结果哪个更精确。
在从CPU到GPU的移植上也需要说明允许的误差范围。
操纵指令生成:
在很多时候,可以通过修改为内部函数来提高性能,如


通过这种方式当然可以提高性能,但是会很慢,所以可以使用nvcc自带的指令来调整优化。
例如

用nvcc –fmad = true编译,生成ptx文件。就可以得到一个算术指令:

而如果用了nvcc –fmad = false,那么结果就是:

可以很明显的看到二者的差别,fmad为true明显比false少了一个步骤。
下图是用于指令生成的编译器标志语句:
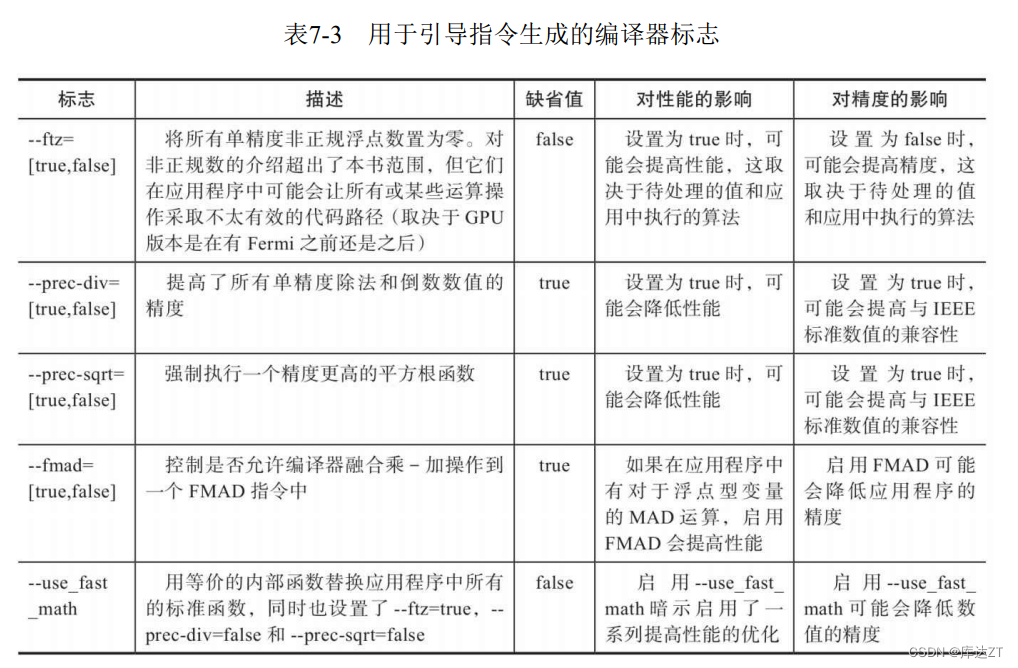
作为原书中的对比


这里我用了__fmul_rn,可以看到与原来的数据还是有偏差的
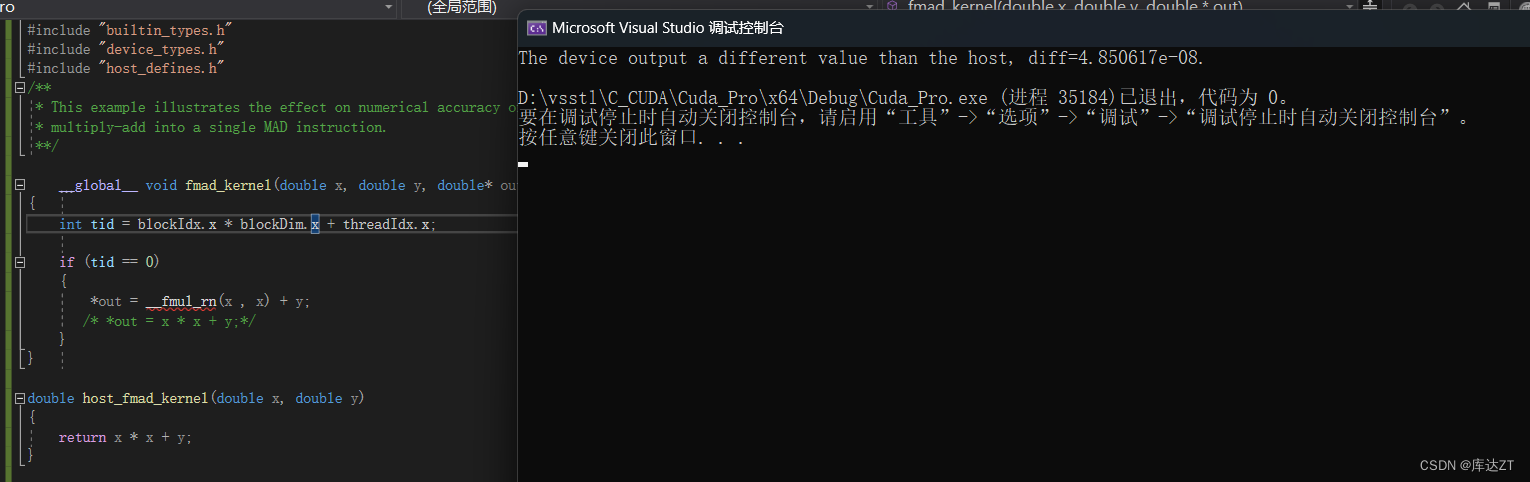
用nsight system分析:
不启用__fmul:
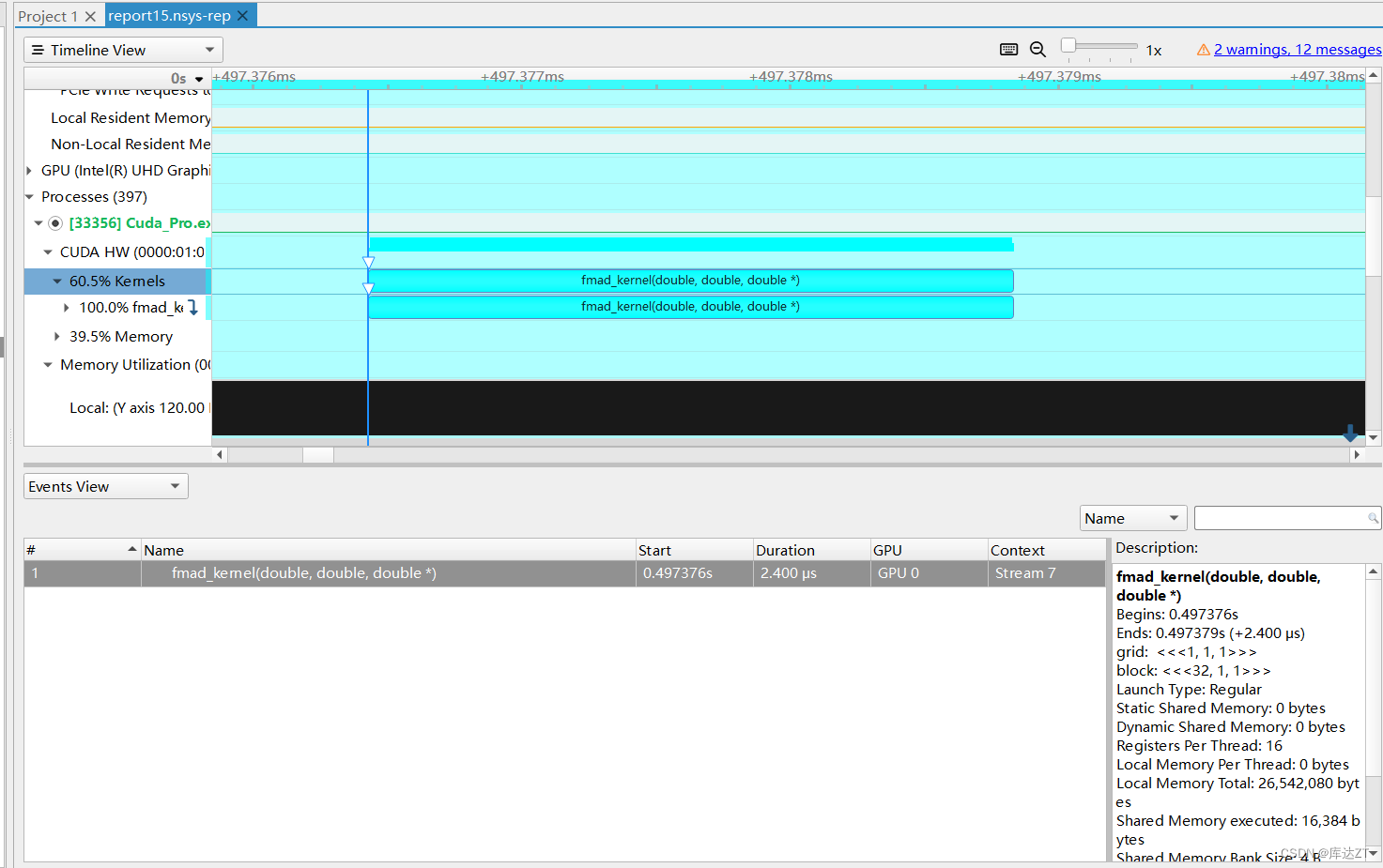
启用__fmul:

这指令级优化怎么还增加了呢?可能是__fmul_rn算法还涉及额外的浮点转化吧
不信邪,加入循环
正常*:
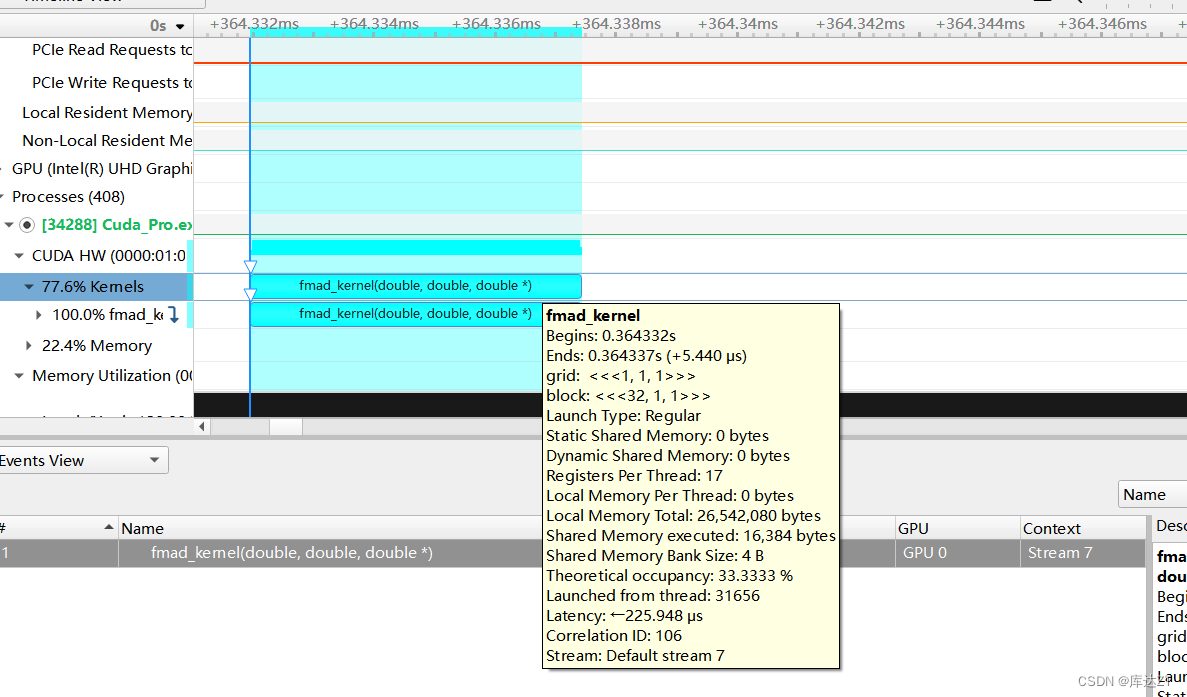
__fmul_rn:
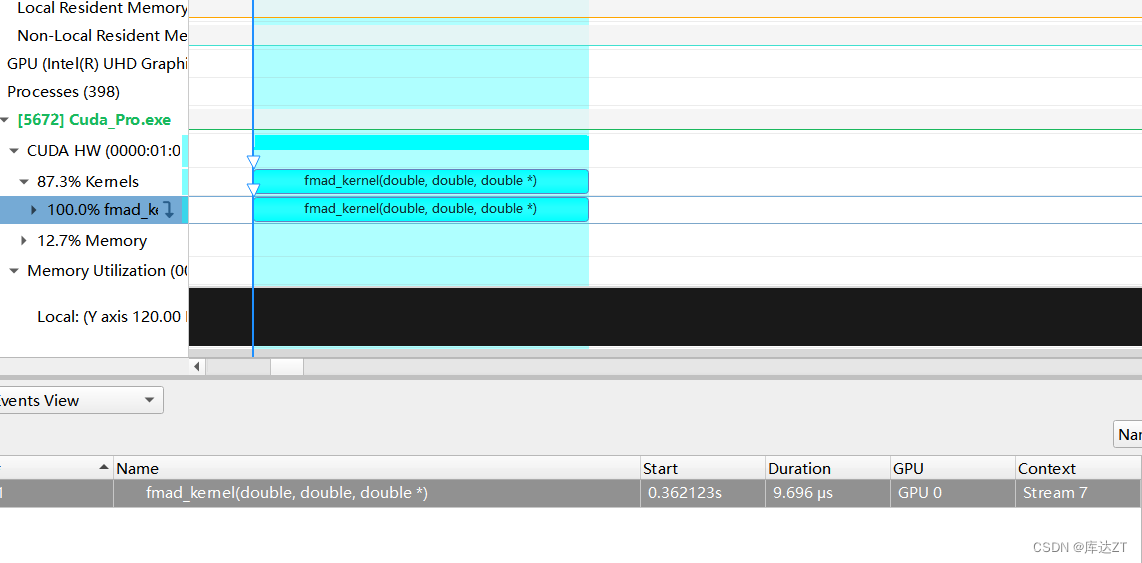
好吧,看来转换确实很费时间。
实验失败,等下课再找找是什么原因。

最后的总结帖图