点击蓝字
关注我们,让开发变得更有趣
作者 | 英特尔 AI 软件工程师 杨亦诚
指导 | 英特尔 OpenVINO 布道师 武卓博士
排版 | 李擎
基于 Llama2 和 OpenVINO™ 打造聊天机器人
Llama 2是 Meta 发布了其最新的大型语言模型,Llama2 是基于 Transformer 的人工神经网络,以一系列单词作为输入,递归地预测下一个单词来生成文本。
这是一款开源且免费的人工智能模型。此前,由于开源协议问题,Llama 1 虽然功能强大,但并不可免费商用。然而,这一次 Meta 终于推出了免费商用版本 Llama 2,借这一机会,我们分享一下如何基于 Llama2 和 OpenVINO 工具套件来打造一款聊天机器人。
项目仓库地址:
https://github.com/OpenVINO-dev-contest/llama2.openvino

注1:由于 Llama2 对在模型转换和运行过程中对内存的占用较高,推荐使用支持 128Gb 以上内存的的服务器终端作为测试平台。
注2:本文仅分享部署 Llama2 原始预训练模型的方法,如需获得自定义知识的能力,需要对原始模型进行 Fine-tune;如需获得更好的推理性能,可以使用量化后的模型版本。
OpenVINO™

模型导出
第一步,
我们需要下载 Llama2 模型,并将其导出为OpenVINO™ 所支持的
IR
格式模型进行部署,这里我们使用 Optimum-Intel 所提供的接口,直接从 Hugging Face 仓库中下载并生成 IR 模型。
ov_model = OVModelForCausalLM.from_pretrained(args.model_id,
compile=False,
from_transformers=True)
ov_model.save_pretrained(model_path)
不过在这之前,我们
首先
需要向 Meta 申请模型下载的许可,方可开始下载,具体如何发送申请可以参考 Llama2 仓库中的说明和引导:https://huggingface.co/meta-llama/Llama-2-7b-hf
在运行项目仓库中的 export_ir.py 脚本后,会在本地指定路径中生成openvino_model.bin和 openvino_model.xml ,前者为模型参数文件,后者为模型结构文件。

模型部署(方案一)
由于目前 Hugging Face 的 Transformer 以及 Optimum 库都已经支持了 Llama2 系列模型的部署,一种比较简便和快捷的做法是,直接使用 Optimum-Intel 来运行整个 Llama2 pipeline,由于 Optimum 中已经预置了完整的问答类模型 pipeline: ModelForCausalLM,并进行了深度的集成, 所以我们只需要调用少量接口,并可以轻松调用 OpenVINO™ 推理后端,实现一个简单问答任务的部署。
ov_model = OVModelForCausalLM.from_pretrained(model_path,
compile=False,
device=args.device)
ov_model.compile()
generate_ids = ov_model.generate(inputs.input_ids,
max_length=args.max_sequence_length)
output_text = tokenizer.batch_decode(generate_ids,
skip_special_tokens=True,
clean_up_tokenization_spaces=False)[0]这里再简单介绍下什么是 Optimum。Optimum 库是 Hugging Face 为了方便开发者在不同的硬件平台部署来自 Transformer 和 Diffuser 库的模型,所打造的部署工具,其中的 Optimum-Intel 库则支持在 Intel 平台部署模型时,调用 OpenVINO™ 工具套件作为模型的推理后端,提升任务性能。
最终效果如下:
“Response: what is openvino ?
OpenVINO is an open-source software framework for deep learning inference that is designed to run on a variety of platforms, including CPUs, GPUs, and FPGAs. It is developed by the OpenVINO Project, which is a collaboration between Intel and the Linux Foundation.
OpenVINO provides a set of tools and libraries for developers to build, optimize, and deploy deep learning models for inference. It supports popular deep learning frameworks such as TensorFlow, PyTorch, and Caffe, and provides a number of features to improve the performance“
OpenVINO™

模型部署(方案二)
由于 Optimum 仍属于“黑箱”模式,开发者无法充分自定义内在的运行逻辑,所以这里使用的第二种方式则是在脱离 Optimum 库的情况,仅用 OpenVINO™ 的原生接口部署 Llama2 模型,并重构 pipeline。
整个重构后 pipeline 如下图所示,Prompt 提示会送入 Tokenizer 进行分词和词向量编码,然后有 OpenVINO™ 推理获得结果(蓝色部分),来到后处理部分,我们会把推理结果进行进一步的采样和解码,最后生成常规的文本信息。这里为了简化流程,仅使用了 Top-K 作为筛选方法。

图:Llama2问答任务流程
整个 pipeline 的大部分代码都可以套用文本生成任务的常规流程,其中比较复杂一些的是 OpenVINO™ 推理部分的工作,由于 Llama2 文本生成任务需要完成多次递归迭代,并且每次迭代会存在 cache 缓存,因此我们需要为不同的迭代轮次分别准备合适的输入数据。接下来我们详细解构一下模型的运行逻辑:

图:Llama2模型输入输出原理
Llama2 模型的输入主要由三部分组成:
· input_ids
是向量化后的提示输入
·attention_mask
用来描述输入数据的长度, input_ids 需要被计算的数据所在对应位置的 attention_mask 值用1表示,需要在计算时被丢弃数据用0表示
· past_key_values.x
是由一连串数据构成的集合,用来保存每次迭代过程中可以被共享的cache.
Llama2 模型的输出则由两部分组成:
· Logits
为模型对于下一个词的预测,或者叫 next token
· present.x
则可以被看作 cache,直接作为下一次迭代的past_key_values.x值
整个 pipeline 在运行时会对 Llama2 模型进行多次迭代,每次迭代会递归生成对答案中下一个词的预测,直到最终答案长度超过预设值 max_sequence_length,或者预测的下一个词为终止符 eos_token_id。
· 第一次迭代
如图所示在一次迭代时(N=1)input_ids 为提示语句,此时我们还需要利用 Tokenizer 分词器将原始文本转化为输入向量,而由于此时无法利用 cache 进行加速,past_key_values.x 系列向量均为空值。
· 第N次迭代
当第一次迭代完成后,会输出对于答案中第一个词的预测 Logits,以及 cache 数据,我们可以将这个 Logits 作为下一次迭代的 input_ids 再输入到模型中进行下一次推理(N=2), 此时我们可以利用到上次迭代中的 cache 数据也就是 present.x,而无需将完整的“提示+预测词”一并送入模型,从而减少一些部分重复的计算量。这样周而复始,将当前的预测词所谓一次迭代的输入,就可以逐步生成所有的答案。
OpenVINO™

聊天机器人
除了 Llama 2 基础版本,Meta 还发布了 LLaMA-2-chat ,使用来自人类反馈的强化学习来确保安全性和帮助性, 专门用于构建聊天机器人。相较于问答模型模式中一问一答的形式,聊天模式则需要构建更为完整的对话,此时模型在生成答案的过程中还需要考虑到之前对话中的信息,并将其作为 cache 数据往返于每次迭代过程中,因此这里我们需要额外设计一个模板,用于构建每一次的输入数据,让模型能够给更充分理解哪些是历史对话,哪些是新的对话问题。
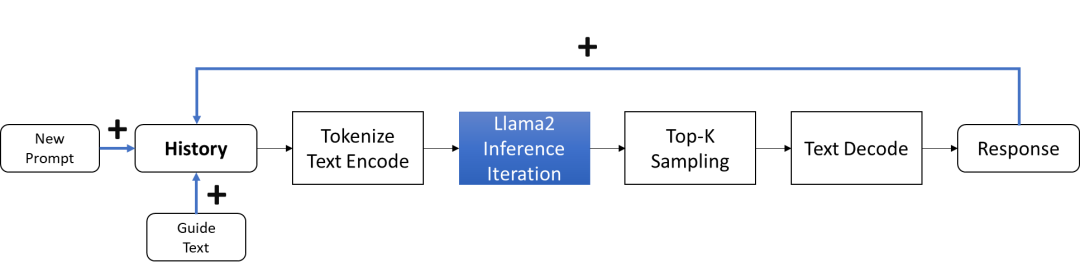
图:Llama2聊天任务流程
这里的 text 模板是由
“引导词+历史记录+当前问题(提示)”
三部分构成:
· 引导词
:描述当前的任务,引导模型做出合适的反馈
· 历史记录
:记录聊天的历史数据,包含每一组问题和答案
· 当前问题
:类似问答模式中的问题
def build_inputs(history: list[tuple[str, str]],
query: str,
system_prompt=DEFAULT_SYSTEM_PROMPT) -> str:
texts = [f'[INST] <<SYS>>\n{system_prompt}\n<</SYS>>\n\n']
for user_input, response in history:
texts.append(
f'{user_input.strip()} [/INST] {response.strip()} </s><s> [INST] ')
texts.append(f'{query.strip()} [/INST]')
return ''.join(texts)我们采用 streamlit 框架构建构建聊天机器人的 web UI 和后台处理逻辑,同时希望该聊天机器人可以做到实时交互,实时交互意味着我们不希望聊天机器人在生成完整的文本后再将其输出在可视化界面中,因为这个需要用户等待比较长的时间来获取结果,我们希望在用户在使用过程中可以逐步看到模型所预测的每一个词,并依次呈现。因此需要利用 Hugging Face 的 TextIteratorStreamer 组件,基于其构建一个流式的数据处理 pipeline,此处的 streamer 为一个可以被迭代的对象,我可以依次获取模型迭代过程中每一次的预测结果,并将其依次添加到最终答案中,并逐步呈现。
streamer = TextIteratorStreamer(self.tokenizer,
skip_prompt=True,
skip_special_tokens=True)
generate_kwargs = dict(model_inputs,
streamer=streamer,
max_new_tokens=max_generated_tokens,
do_sample=True,
top_p=top_p,
temperature=float(temperature),
top_k=top_k,
eos_token_id=self.tokenizer.eos_token_id)
t = Thread(target=self.ov_model.generate, kwargs=generate_kwargs)
t.start()
# Pull the generated text from the streamer, and update the model output.
model_output = ""
for new_text in streamer:
model_output += new_text
yield model_output
return model_output当完成任务构建后,我们可以通过 streamlit run chat_streamlit.py 命令启动聊天机器,并访问本地地址进行测试。这里选择了几个常用配置参数,方便开发者根据机器人的回答准确性进行调整:
· max_tokens
: 生成句子的最大长度。
· top-k:
从置信度对最高的k个答案中随机进行挑选,值越高生成答案的随机性也越高。
· top-p:
从概率加起来为p的答案中随机进行挑选, 值越高生成答案的随机性也越高,一般情况下,top-p会在top-k之后使用。
· Temperature
: 从生成模型中抽样包含随机性, 高温意味着更多的随机性,这可以帮助模型给出更有创意的输出。如果模型开始偏离主题或给出无意义的输出,则表明温度过高。
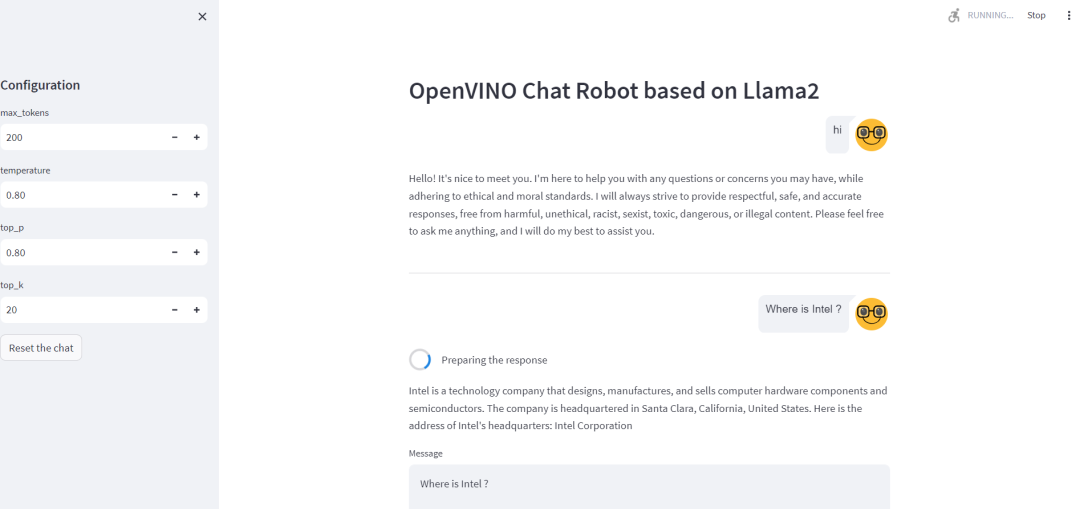
注3:由于Llama2模型比较大,首次硬件加载和编译的时间会相对比较久
OpenVINO™

总结
作为当前最火爆的开源大语言模型,Llama2 凭借在各大基准测试中出色的成绩,以及支持微调等特性被越来越多开发者所认可和使用。利用 Optimum-Intel 和 OpenVINO™ 构建 Llama2 系列任务可以进一步提升其模型在英特尔平台上的性能,并降低部署门槛。
参考资料
1.Optimum-Intel:
https://github.com/huggingface/optimum-intel
2.Optimum:
https://huggingface.co/docs/optimum
3.GPT2 notebook samples: https://github.com/openvinotoolkit/openvino_notebooks/tree/dd77a4c47312fdfdc2e43e27aa488e2802733760/notebooks/223-text-prediction
4.Llama2 Hugging Face:
https://huggingface.co/meta-llama/Llama-2-7b-chat-hf
OpenVINO™
–END–
你也许想了解(点击蓝字查看)⬇️➡️ OpenVINO™ DevCon 2023重磅回归!英特尔以创新产品激发开发者无限潜能➡️ 5周年更新 | OpenVINO™ 2023.0,让AI部署和加速更容易➡️ OpenVINO™5周年重头戏!2023.0版本持续升级AI部署和加速性能➡️ OpenVINO™2023.0实战 | 在 LabVIEW 中部署 YOLOv8 目标检测模型➡️ 开发者实战系列资源包来啦!➡️ 以AI作画,祝她节日快乐;简单三步,OpenVINO™ 助你轻松体验AIGC
➡️ 还不知道如何用OpenVINO™作画?点击了解教程。➡️ 几行代码轻松实现对于PaddleOCR的实时推理,快来get!➡️ 使用OpenVINO 在“端—边—云”快速实现高性能人工智能推理➡️ 图片提取文字很神奇?试试三步实现OCR!➡️【Notebook系列第六期】基于Pytorch预训练模型,实现语义分割任务➡️使用OpenVINO™ 预处理API进一步提升YOLOv5推理性能扫描下方二维码立即体验
OpenVINO™ 工具套件 2023.0点击 阅读原文 立即体验OpenVINO 2023.0
文章这么精彩,你有没有“在看