一、首先介绍几种常见的架构
批流一体架构面临的挑战
传统架构
数据仓库的架构随着业务分析实时化的需求也在不断演进,但在数据分析平台的最初起步阶段,为了满足实时分析需求,传统方案的做法一般都会将实时分析和历史批量数据分析拆分成2种不同的独立架构,形成如下图片所示的异构环境:

在这样完全不同的独立异构环境下,不管是从部署架构层面,还是从数据存储介质层面都可以说是完全不一致的,这就使得在技术实现上面临比较大的挑战。
分别维护实时分析与离线分析两套不同架构的服务,对于系统运行的稳定性,后续应用升级,故障处理等都会比较复杂和繁琐;
分别设计、管理实时分析与离线分析两套不同的数据模型,离线分析可以通过关联获取更加丰富的数据,而实时分析为了保障数据时效性能只能是简单的宽表形式进行处理,而且开发流程较繁琐;
因实时数据与离线数据存储介质的割裂,最终导致两者数据在存储时就相互隔离,更无法对两者进行统一的数据周期管理;
在数据服务层中需要根据应用层进行定制化的开发,为不同的应用提供不同的数据服务,同时也使得这个查询服务层的维护成本增加不少。
以上这些限制使开发和运维工作都变得的相当困难,不能灵活地应对业务敏捷多变的取数需求。
Lambda 架构
于是基于这种传统方案的进一步演化,在大数据生态下诞生的Lambda架构开始崭露头角。在Lambda架构中,数据处理分为 Speed Layer、Batch Layer 和 Serving Layer 三个部分。
Speed Layer 负责实时处理数据,计算逻辑直接对接流数据,尽量缩短数据处理的延迟,但由于流数据天生的数据质量不可控,尽管缩短了数据处理时间,但可能牺牲数据的正确性和完整性;
Batch Layer 负责批量规模性处理数据,可以保证数据的正确性和处理规模
Serving Layer 负责融合 Speed 和 Batch 两个部分的数据能力,对外提供简单一致的数据访问视图。
但在实际应用的过程中,发现 Lambda 架构也存在着一些不足,虽然它使用的是同一架构环境,但是它也同样存在类似传统架构那样较复杂的维护工作。企业需要维护两个复杂的分布式系统,即Batch Layer和Speed Layer,并且保证他们逻辑上产生相同的结果输出到服务层中。

Kappa 架构
因此为了将Batch Layer和Speed Layer进行统一架构,业界由Kafka团队提出了新的Kappa架构,基于Streaming是新的DB(数据库)的设计思想,要将所有的数据消费都基于Kafka,形成统一的数据出口,后续数据处理都基于流式(Kafka)数据源。

这个架构是随着Kafka上数据加工能力的提升而受到大家关注(特别是Flink框架加持,显著提升流数据处理能力)。Kappa试图解决多个计算引擎带来的开发、运维难题,只保留实时一套代码和数据。但在实践中,我们发现数据处理的复杂度不完全是一个单向的流式处理可以全部支持的,比如数据模型的演化,历史数据的修补更新,缓慢变化维的处理等等,都需要更灵活的数据建模能力。
基于上述对传统方案、Lambda、Kappa 这些数据架构的讨论,以及企业应用的实际需求,我们认为在数据架构的灵活性、加工逻辑的便捷性、数据模型治理等角度还有更优解。接下来,我们将从批流一体架构这关键部分:数据模型、数据生命周期以及查询服务,进行探讨,为正在进行批流一体选型企业提供一些参考。
基于 Kyligence 的批流一体大数据分析架构探索
基于统一数据模型、生命周期管理、查询服务等批流一体分析中的关键诉求,以及对上述各种方案的探索,最后我们选取基于Lambda架构对Kyligence产品进行升级,打造出批流一体的企业级产品应用。
数据模型
我们知道数据的分析都离不开模型设计作为基础,模型是数据加工的目标和方法,是数据计算逻辑,也是数据分析的对象。这里我们把模型分为实时模型和历史模型,实时模型为追求数据处理的时效性设计,因此要避免计算逻辑复杂,历史模型为分析的完整性设计,因此需要更丰富的指标含义和数据治理能力。从业务分析的角度上出发,两者之间还是存在共同的特征,两者之间的关系可以用如下图示来总结。

从图上实时模型与历史模型的共同特点分析,两者模型是融合统一的。比如两个模型中的事实表通常都是相同的,可以使用公共的分析维度和指标语义进行数据分析,这就要求批流一体的平台可支持两个模型的统一定义,设计和管理,避免模型重复开发和模型不一致。历史模型是实时模型的超集,历史模型涵盖了实时模型的能力,增强了分析的能力(更多维度、更细的粒度、全局去重指标等)。
由于处理实时和历史数据的计算引擎不同,利用其各自优势,实时模型继续使用流式计算引擎对接流式数据源,历史模型基于大数据平台的并行能力,进行大规模多数据源的融合计算。同时历史模型利用数仓理论中成熟的多维分析方法论,提供缓慢变化维管理、历史数据刷新等能力,增强数据治理。通过对模型定义的统一管理,避免了数据处理逻辑的重复开发,更保证了指标定义的一致性。
数据生命周期
模型统一了,数据还是不同计算引擎加工,不可以允许两份数据共同提供查询服务,会引起服务能力的不一致,典型是数据结果重复。因此还需要解决数据生命周期如何管理。实时数据流与历史数据集,可以说是两条完全平行不相同的数据流,如下图所示:
需要将两份存储进行统一的数据规整,面对不同的分析场景处理方式各有不同。实时数据为保证时效性,会牺牲一定的数据“质量”(原始数据采集质量不可控,数据晚到,缺少数据质量实时修正流程等),这对于一些监控场景是够用的,可以接受“不那么较真”的数据质量;对于分析型的场景来说这样是不可容忍的,需要保证数据的正确性,需要对实时数据进行相应的“修订”才可以和历史数据进行统一的整合。
所以当实时流数据“沉淀”为历史数据时,需要可以有一定的流程进行实时数据的规整和修正,可以通过实时处理修正(数据重放),也可以是通过离线处理修正(一般称为Enrichment,比如关联更多数据源),这就要求批流一体的平台需要有不同的场景下的数据治理能力,不能简单把实时数据沉淀为历史数据,而要提供多种数据修正的处理能力。
查询服务
SQL语言是数据分析师最熟悉的查询方式,提供标准的SQL语法支持,成为对接数据应用层面尤为关键的一环。过去我们曾采用HBase、Redis等多种技术实现查询服务层,甚至要求实时层和历史层采用不同的API,由应用自行判断合适的查询引擎,这给应用开发带来了更高的门槛。
因此,为了简化服务层接口,需要针对实时分析与历史分析的不同业务场景,自动将查询请求路由到相应的数据集进行检索并返回,同时还需要具备将两者数的查询融合能力,而不是分别从异构系统中取出数据,再在Data Service层用笨拙的编码或人工方式进行合并。这也就要求批流一体的平台既要支持实时分析与历史分析的独立查询,也要支持两者数据查询的融合能力。
Lambda 和 Kappa 的场景区别:
- Kappa 不是 Lambda 的替代架构,而是其简化版本,Kappa 放弃了对批处理的支持,更擅长业务本身为 append-only 数据写入场景的分析需求,例如各种时序数据场景,天然存在时间窗口的概念,流式计算直接满足其实时计算和历史补偿任务需求;
- Lambda 直接支持批处理,因此更适合对历史数据有很多 ad hoc 查询的需求的场景,比如数据分析师需要按任意条件组合对历史数据进行探索性的分析,并且有一定的实时性需求,期望尽快得到分析结果,批处理可以更直接高效地满足这些需求。
-
Kappa+
-
Kappa+是 Uber 提出流式数据处理架构,它的核心思想是让流计算框架直读 HDFS类的数仓数据,一并实现实时计算和历史数据 backfill 计算,不需要为 backfill 作业长期保存日志或者把数据拷贝回消息队列。Kappa+ 将数据任务分为无状态任务和时间窗口任务,无状态任务比较简单,根据吞吐速度合理并发扫描全量数据即可,时间窗口任务的原理是将数仓数据按照时间粒度进行分区存储,窗口任务按时间序一次计算一个 partition 的数据,partition 内乱序并发,所有分区文件全部读取完毕后,所有 source 才进入下个 partition 消费并更新 watermark。事实上,Uber 开发了Apache hudi 框架来存储数仓数据,hudi 支持更新、删除已有 parquet 数据,也支持增量消费数据更新部分,从而系统性解决了问题2存储的问题。下图3是完整的Uber 大数据处理平台,其中 Hadoop -> Spark -> Analytical data user 涵盖了Kappa+ 数据处理架构。
二、典型实时业务场景
首先我们来看一个典型的实时业务场景,这个场景也是绝大部分实时计算用户的业务场景,整个链路也是一个典型的流计算架构:把用户的行为数据或者数据库同步的Binlog,写入至kafka,再通过Flink做同步任务,订阅kafka消费的实时数据,这个过程中需要做几件事情,比如Preprocessing(预处理),在处理的过程中做Online Training(在线训练),在线训练过程中需要关联一些维表或者特征,这些特征可能可以全量加载到计算节点里面去,也有可能非常大,就需要用HBase做一个高并发的点查,比如我们做一些样本也会写入到HBase中去,形成一个交互过程,最后实时产生的采样数据或者训练模型推到搜索引擎或者算法模块中。以上就是一个很典型的Machine Learning的完整链路。
1.2 越来越复杂的架构
以上场景展示的链路与离线链路是相辅相成的,也有一些公司实时的链路还没有建立起来,用的是离线链路,不过这套链路已经是一个非常成熟的方案了。如果我们把这个链路变得更加复杂一些,看看会带来什么样的问题。首先我们把刚刚的链路做一个变化,实时数据写入kafka,再经过Flink做实时的机器学习或者指标计算,把结果写入到在线服务,例如HBase或者Cassandra用来做点查,再接入在线大盘,做指标的可视化展现。
这里面产生的一个问题就是:在线产生的数据和样本,如果想对它们做一个分析,基于HBase或者Cassandra的分析能力是非常弱的且性能是非常差的。
那么怎么办呢?
有聪明的开发者们可能就有一些实现方式如下:
HBase或者Cassandra不满足分析需求,就把实时数据写入至适合数据分析的系统中,比如ClickHouse或者Druid,这些都是典型的列存架构,能构建index、或者通过向量化计算加速列式计算的分析,再对接分析软件,对数据做实时报表、实时分析展现等,以此链路来解决实时高效分析的问题。
但上面的架构中,还有一些额外的需求,就是要将实时产生的数据数据归档至离线系统,对离线数据做一个基于历史的全量分析,基于此开发者们最常用的链路就是把实时数据离线的归档至Hive中,在Hive中做T+1天或者其他的离线算法。通过Hive对离线数据的处理来满足离线场景的需求。
但是业务既有实时写入的数据又有离线的数据,有时我们需要对实时数据和离线数据做一个联邦查询,那应该怎么办呢?
基于现市面上的开源体系,开发者们最常用的架构就是基于Drill或者Presto,通过类似MPP的架构层做多数据的联邦查询,若是速度不够快,还能通过Druid、ClickHouse等做查询加速。
以上联邦查询的链路有个问题就是,QPS很难上去,比如前端调用需要每秒钟几百上千的QPS,如果几百上千的QPS全部通过加速层来做,那性能肯定是有所下降的,这时应该怎么办呢?最常见的解决方案就是在常见的加速层再加一个cache,用来抵挡高并发的请求,一般是加Redis或者Mysql用来cache数据,这样就能提供server以及在线服务的能力。
1.3 典型的大数据Lambda架构
以上就是绝大部分公司所使用的大数据架构,也有很多公司是根据业务场景选择了其中一部分架构,这样既有实时又有离线的大数据完整架构就搭建出来,看起来很完美,能实际解决问题,但是仔细想想,里面藏了很多坑,越往后做越举步维艰,那么问题在哪呢?现在我们来仔细看一下。
其实这套大数据方案本质上就是一个Lambda架构,原始数据都是一个源头,例如用户行为日志、Binlog等,分别走了两条链路:一条是实时链路,也就是加速层(Speed Layer),通过流计算处理,把数据写入实时的存储系统;另一条链路就是离线链路,也就是批计算,最典型的就是将数据归档至Hive,再通过查询层如Spark对数据做加速查询,最后再对接在线应用、大盘或者第三方BI工具。
1.4 典型大数据架构的痛点
针对市面上这些开源产品,就存储而言,我们来逐一分析,这些产品是否都能具备满足业务需求的能力。
首先是基于离线存储的Hive,其次是提供点查询能力的HBase、Cassandra、然后是MPP架构号称能面向HTAP的Greenplum、以及最新兴起的用于做快速分析的Clickhouse等等都是基于解决方案而面世的存储产品。
但以上的每个存储产品都是一个数据的孤岛,比如为了解决点查询的问题,数据需要在HBase里面存储一份;为了解决列存的快速分析,数据需要在Druid或者Clickhouse里面存一份;为了解决离线计算又需要在Hive里面存储一份,这样带来的问题就是:
1)冗余存储
数据将会存储在多个系统中,增加冗余存粗。
2)高维护成本
每个系统的数据格式不一致,数据需要做转换,增加维护成本,尤其是当业务到达一定量级时,维护成本剧增。
3)高学习成本
多个系统之前需要完全打通,不同的产品有不同的开发方式,尤其是针对新人来说,需要投入更多的精力去学习多种系统,增加学习成本。
1.5 简化的大数据架构
面对这样一个无比冗余无比复杂的系统,我们应该怎么去解决这些问题呢?我们可以对Lambda架构做一个简化。其实业务的本质就是将数据源做一个实时处理或者离线处理(批处理),从业务场景出发,我们希望不管是实时数据还是离线数据,都能统一存储在一个存储系统里面,而且这个存储还必须要满足各种各样的业务需求。这样听起来很玄乎,感觉这个产品需要支持各种各种的场景,非常复杂。但是如果我们能把架构做成这样,将会非常完美,这样就从本质上解决了流批统一的计算问题,一套SQL既能做流计算又能做批计算,再深挖其底层原理,还解决了存储问题,流数据和批数据都统一存储在同一个产品。
看起来很完美的Data Lakes
针对以上简化的架构,我们可以看看开源社区为了解决这些问题所推出的一些产品,例如Data Lakes。
首先采集的数据有统一的存储,不管是HDFS、OSS还是AWS,数据以增量的形式存储在数据湖里,再通过查询层不管是Hive、Spark还是Flink,根据业务需求选择一个产品来做查询,这样实时数据以及离线数据都能直接查询。整个架构看起来很美好,但是实际问题在于:
1)数据增量写入不满足实时性
开源的实时写入并不是实时写入,而是增量写入。实时和增量的区别在于,实时写一条数据就能立马查询可见,但是增量为了提高吞吐会将数据一批一批的写入。那么这套方案就不能完全满足数据实时性的要求。
2)查询的QPS
我们希望这个架构既能做实时分析,又能做流计算的维表查询,存储里面的数据能否通过Flink做一个高并发的查询,例如每秒钟支持上千万上亿QPS的查询?
3)查询的并发度
整个方案本质都是离线计算引擎,只能支持较低的并发,如果要支持每秒钟上千的并发,需要耗费大量的资源,增加成本。
综上所述,这个方案目前还不能完全解决问题,只能作为一个初期的解决方案。
数据湖iceberg
不同于hudi, iceberg宣称支持 Full Schema evolution,支持对Schema增加列、删除列、更新列、重名列、重排序列,由于schema逻辑独立于上层的计算引擎及底层的文件存储格式,所以iceberg的schema evolution可以保证没有任何副作用,调整schema只会对新写入的数据有影响。
在设计上与上层计算引擎及底层文件存储格式进行分离,具有很好的扩展性。
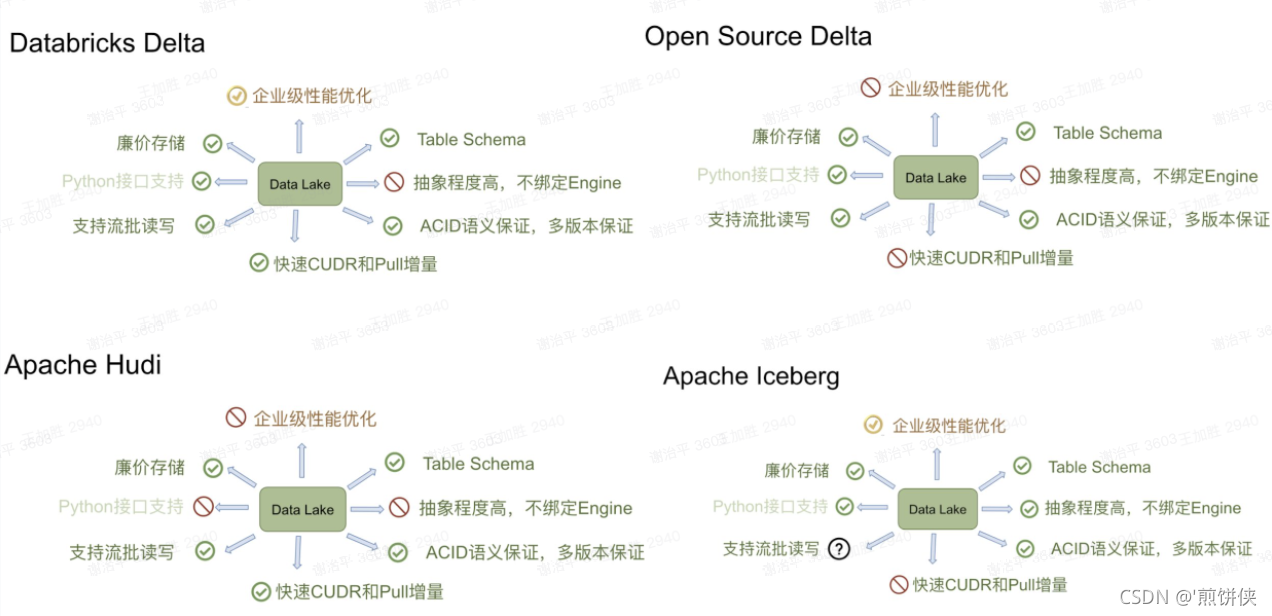
使用的iceberg作为我们的数据存储然后flink和spark作为流批的计算,其实也是基于类似lambda的方式去实现业务方案。

应用iceberg,可以存储数据,对数据进行修改,而且可以拿到对比变化的数据,然后再同步修改Doris的数据,可以使用Doris的unique模式。然后实时数据使用flink实时计算,离线数据使用spark批处理入湖,最后再联合查询展示。
参考文章:
1.
https://zhuanlan.zhihu.com/p/71841447