SVM:最大间隔分类
在理解SVM的过程中,我也参考了很多别人的文章,有些可能我还能找到记录,这部分我将会在文末附上链接,但更多的可能找不到链接了,见谅。
另:实际上作者觉得SVM是一个很大的话题,我的理解可能只是其中小小的一部分,如果我说的有问题或者大家有什么补充的,欢迎在评论区留言交流。
要想理解SVM,有一些基础知识是需要先了解的,下面我们先介绍一下这些基础知识:
1.超平面
超平面是n维欧氏空间中余维度等于一的
线性
子空间,也就是必须是(n-1)维度。这是平面中的直线、空间中的平面之推广(n大于3才被称为“超”平面),是纯粹的数学概念,不是现实的物理概念。因为是子空间,所以超平面一定经过原点。(以上内容来自百度百科)
从以上定义我们可以知道,如果线性空间是n维的,那么超平面就应该是n-1维的,涉及到高维平面时,我们无法直观的去了解它,因此,在这里我们采用二维平面来进行解释(但实际上这并不是超平面,这一点我们应该要了解)
在二维空间中,我们用点集
来表示一条直线,则应有:
式1.1
在这里,我们令向量
,则式1.1可表示为:
式1.2
在点集i上取一点p(px,py),显然该点满足式1.2,即:
式1.3
即有
成立,带入到式1.2中,有如下式子成立:
式1.4
可以看到,向量i-p显然是和点集i表示的直线是同向的,用m表示该向量,则应有:
式1.5
即,n为点集i表示的直线的法向量,因此,我们可以得到超平面的表达式:
式1.6
其中,w和x都是n维列向量,x是平面山的点,w是超平面的法向量,b是超平面到原点的距离(其实这一点我还是有疑问,因为定义里面有说到超平面是过原点的,在这里我感觉b应该是某种情况下的截距之类的,但是由于涉及到高维空间,所以不是那么好理解,后面如果有新的想法会更新)。
有了超平面这一概念,下面我们就来求解超平面和点之间的间距公式,在这里介绍两种间隔,一种是函数间隔,另一种是几何间隔。
对于给定的训练数据集T和超平面
,定义超平面关于数据集中样本点
的函数间隔为:
式1.7
函数间隔可以表示分类预测的正确性和确信度,当对样本点的分类正确时,d应该是正的(显然这是好理解的,因为有一个
标签在这里 里。但是我们同时应该注意到,根据超平面的定义,如果我们等比例的改变w和b,那么超平面实际上是不改变的,还是原来的超平面,但这时候函数间隔却会成比例的改变,例如
,因此,我们引入另一个概念:几何间隔
在几何间隔中,我们对法向量w施加一些约束,以此来确保间隔是固定的(可以理解为当等比例扩大w和b时,整个超平面会等比例扩大,那么点和点之间的间距就会扩大),例如令||w||=1,即对于给定的训练数据集T和超平面
,定义超平面关于数据集中样本点
的几何间隔为:
式1.8
很显然,对于几何间隔,当我们再次等比例改变w和b时,几何间隔是不变的,也就是说,只要超平面不发生变化,几何间隔是不变的。
2.拉格朗日乘子法
拉格朗日乘子法是一种寻找多元函数在一组约束条件下的极值的方法,通过引入拉格朗日乘子,可将有d个变量与k个约束条件的最优问题转化为具有d+k个变量的无约束最优化问题。
假设原始问题为求解f(x)的最小值,即
式2.1
式2.2
式2.3
我们构造拉格朗日函数如下:
式2.4
首先我们来考虑
这一约束条件,我们假设h(x)与f(x)之间的位置相对关系如下图所示(当然,他们之间可能是别的位置关系,但是这对我们的推导实质上没有什么影响):
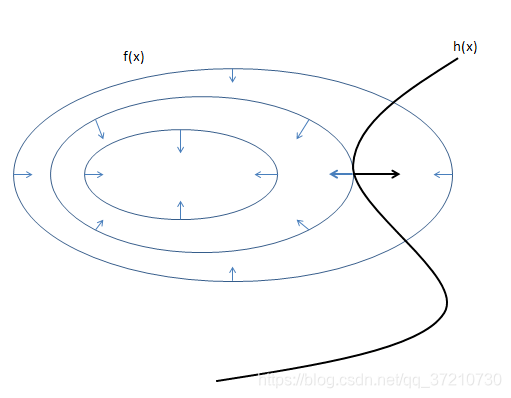
如图所示,圆圈是f(x)的等值线(类似于等高线),黑线表示约束
,显然,只有当h(x)和等值线相切时才能取到极值点(若不是相切点,那么势必能找到x’使得f(x’)<f(x)),因此在切点必有▽f(x)与▽h(x)(梯度)在一条直线上,由此我们可以得到如下等式成立:
▽f(x)+
▽h(x)=0,
可以等于0,即相切点正好是f(x)的最小值点,所以
的取值实际上是无限制的。
然后我们来考虑
这一约束条件,对于
和
来说,由于前面的不等式约束条件
,其与f(x)的关系如下图所示:
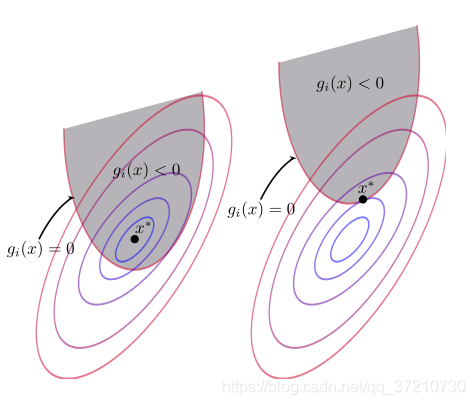
可以看到,函数
和约束条件
之间存在两种位置关系:
1.函数
的最小值点
在
内,如左图所示,此时约束条件
在求解最小值的过程中并不起作用,即,相当于令
为0,随后按照正常的求偏导令其为0的方法来求解最小值。
2.函数
的最小值点
在
上,如右图所示,应该注意到的是,在此时的x*点上,g(x)与f(x)之间是相切的关系,这是很好理解的,和前面的
的约束条件一样考虑就行,如果不是相切关系那么函数值还会向着令f(x)更小的方向去走,那么x*就不是最小值点,因此会有g(x)与f(x)在x*点是相切关系。因而有在点x*处f(x)和g(x)的梯度在同一条直线上,即▽f(x) +
▽g(x)=0,显然这也是好理解的,同一条直线上的两个向量,必定可以通过参数
使二者相加为0,同时需要注意的是,在点x*处,必有▽f(x)和▽g(x)是异号的,直接来说,就是在点x*出,f(x)的梯度方向是向着g(x)<0内部的(因为与之反向的是f(x)减小的方向),而相反的,g(x)的梯度值是向着g(x)<0外部的(因为与之相反的方向是g(x)减小的方向)。
综上所述,
和g(x)的范围有两种情况,一:
=0,g(x)<0;二:
>0,g(x)=0,因此我们可以得到以下KKT条件:
式2.5
式2.6
式2.7
3.拉格朗日对偶性
在约束最优化问题中,常常利用拉格朗日对偶性将原始问题转换为对偶问题,通过解决对偶问题而得到原始问题的解。相对于原始问题来说,对偶问题有一些非常良好的性质,如下:
- 对偶问题的对偶是原问题;
- 无论原始问题是否是凸的,对偶问题都是凸优化问题;
- 对偶问题可以给出原始问题的一个下界;
- 当满足一定条件时,原始问题与对偶问题的解是完全等价的。
原始问题:
原始问题即式2.1~式2.3,在这里,我们继续使用前面构造的拉个朗日函数,即式2.4,对于
,我们构造一个关于变量x的函数
,令
,由约束条件式2.2~式2.3知:
1.若存在某一
不满足约束条件,即对应的的有
或有
,此时令对应的
或
,则对应的有
;
2.所有的
均满足约束条件,即
且
,显然,此时有
(此时要想求得拉格朗日函数的最大值,必有
)
因此,对于原始问题(式2.1~式2.3),我们就可以转换为如下表达式:
式3.1
称之为拉格朗日函数的极大极小值问题,定义原始问题的最优值
式3.2
为原始问题的值。
对偶问题:
定义
式3.3
再考虑极大化式3.3,即
式3.4
该极大化问题我们称之为广义拉格朗日函数的极大极小问题。将其表示为约束最优化问题,如下所示:
式3.5
式3.6
称为原始问题的对偶问题。定义对偶问题的最优值
式3.7
称为对偶问题的值。
二者关系:
当以下条件成立时,取等号:

以上,我们介绍完了需要提前了解的一些知识,下面,我们来正式解读SVM
直接的说,SVM就是我们现在有一个n维空间点集,其中的点分为两类,我们需要找到一个n-1维的超平面按照二者之间的最大间距将其分离开来。
我们知道超平面可以表示为
,则样本空间中任意点x*到超平面的距离可以表示为如下形式
式4.1
其中,
,x为超平面上一点,x*为样本空间中一点。
假定超平面能对训练样本进行正确分类,那么应该存在:
1.
(样本为正)
2.
(样本为负)
即:
这里,
表示超平面和训练数据集之间的几何间距(正确分类的情况下),为了方便,我们在这里取值
(实际上,
的取值对后面的求解约束问题没有影响,你可以取任何正值),因而两个异类支持向量到超平面的
几何距离
之和为:
SVM的任务就是求解一个超平面,使得
取得最大值。这样,生成的模型在对未知的数据集进行预测时,就会有较好的鲁棒性。
显然,要求解
的最大值,我们需要求解
的最小值,于是,我们就得到了SVM的基本形式,如下:
式4.2
式4.3
有了式4.2,4.3,引入拉格朗日乘子
构建拉格朗日函数
如下:
式4.4
利用解拉格朗日函数的方法,分别求函数对
的偏导,并令其为0可得到如下式子:
式4.5
式4.6
将式4.5,式4.6回带式4.4,即可消去w和b,得到如下等式:
式4.7
考虑对偶问题:
式4.8
解出
之后,即可求出w和b,进一步就可以得到模型:
式4.9
需要注意的是,在求解
时,由于其是拉格朗日乘子,且存在不等式约束 式4.3,因而
应该满足KKT条件。下面,主要结合代码讲述一种求解
的方法,称为序列最小化算法SMO,有Platt在1998年提出。
首先,明确我们要求解的对偶问题:
式4.10
式4.11
,
式4.12
在仅考虑
时,式4.11和式4.12可重写为下式:
式4.13
其中
式4.14
用式4.13消去式4.10中的
即可以得到一个关于
的单变量二次规划问题,很容易就可以求得解。
下面贴上简化版SMO算法源码部分:
def selectJrand(i, m):
j = i
while(j == i):
j = int(random.uniform(0, m))
return j
def clipAlpha(aj, H, L):
if aj > H:
aj = H
if L > aj:
aj = L
return aj
# 根据alpha求解w
def weight(data, label, alphas):
dataMatrix = np.mat(data)
labelMatrix = np.mat(label).transpose()
m, n = dataMatrix.shape
w = np.mat(np.zeros((1, n)))
for i in range(m):
if alphas[i] > 0:
w += labelMatrix[i] * alphas[i] * dataMatrix[i, :]
# 将数组或者矩阵转换为列表
return w.tolist()
def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
'''
Simplified SMO algorithm
input: dataMatIn(list) 样本各属性值
classLabels(list) 各样本对应标签
C() 软间隔最大化的松弛系数对应的惩罚因子,也是约束条件中alpha的上界(对于线性可分数据集,C作用不大;对于线性不可分数据集,结果对C敏感)
toler() 容错率,偏离KKT条件的容错率
maxIter(int) 外层循环迭代次数
output: b(float) 偏移量
alphas(mat) ai的值
'''
dataMatrix = mat(dataMatIn)
labelMat = mat(classLabels).transpose()
b = 0
m, n = shape(dataMatrix)
# 初始化alpha=0,alpha为样本个数,一个样本对应一个alpha
alphas = mat(zeros((m, 1)))
iter = 0
while (iter < maxIter):
alphaPairsChanged = 0
for i in range(m):
fXi = float(multiply(alphas, labelMat).T * (dataMatrix * dataMatrix[i, :].T)) + b # zhou-P124-----f(x)=(ai)(yi)(xi.T)x+b
Ei = fXi - float(labelMat[i])
# ai等于C时,则允许的误差变量ui为0,因为C = ai + ui,也就是
'''
检验第i个样本点是否满足KKT条件,若满足会跳出本次内循环(不更新这个alpha),进行下一次内循环
若不满足,看它是否超过toler,若不是,跳出本次内循环(不更新这个alpha),进行下一次内循环
若是,则继续选择aj,计算gx,E,eta,进而求得aj解析解,进而求得ai解析解,进而更新b值
'''
if ((labelMat[i] * Ei < -toler) and (alphas[i] < C)) or ((labelMat[i] * Ei > toler) and (alphas[i] > 0)):
j = selectJrand(i ,m)
fXj = float(multiply(alphas, labelMat).T * (dataMatrix * dataMatrix[j, :].T)) + b
Ej = fXj - float(labelMat[j])
# python会通过引用的方式传递所有列表,因此要分配新的内存
alphaIold = alphas[i].copy()
alphaJold = alphas[j].copy()
# 计算剪切边界(几何计算,统计学习方法)
if (labelMat[i] != labelMat[j]):
L = max(0, alphas[j] - alphas[i])
H = min(C, C + alphas[j] - alphas[i])
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
if L == H:
print('\nL == H\n')
continue
# alpha的最优修改量,这一步是对原始SMO算法的简化
eta = 2.0 * dataMatrix[i, :] * dataMatrix[j, :].T - dataMatrix[i, :] * dataMatrix[i, :].T - dataMatrix[j, :] * dataMatrix[j, :].T
if eta >= 0:
print('\n eta >= 0 \n')
# continue 是退出当前for循环进入下一次循环
continue
# 根据统计学习方法中的结果公式得到的alphaj的解析解
alphas[j] -= labelMat[j] * (Ei - Ej) / eta
# 将aj的值限制在剪切域内
alphas[j] = clipAlpha(alphas[j], H, L)
if (abs(alphas[j] - alphaJold) < 0.00001):
print('\nj not moving enough\n')
continue
# 约束条件,根据alphaJ的值来求解alphaI的值
alphas[i] += labelMat[j] * labelMat[i] * (alphaJold - alphas[j])
# 更新B值,根据alpha是否在0~C决定更新的b值
b1 = b - Ei - labelMat[i] * (alphas[i] - alphaIold) * dataMatrix[i, :] * dataMatrix[i, :].T -\
labelMat[j] * (alphas[j] - alphaJold) * dataMatrix[i, :] * dataMatrix[j, :].T
b2 = b - Ei - labelMat[i] * (alphas[i] - alphaIold) * dataMatrix[i, :] * dataMatrix[j, :].T -\
labelMat[j] * (alphas[j] - alphaJold) * dataMatrix[j, :] * dataMatrix[j, :].T
if (0 < alphas[i]) and (C > alphas[i]):
b = b1
elif (0 < alphas[j]) and (C > alphas[j]):
b = b2
else:
b = (b1 + b2) / 2.0
alphaPairsChanged += 1
print('\niter: %d i %d, pairs changed %d\n' % (iter, i, alphaPairsChanged))
if (alphaPairsChanged == 0):
iter += 1
else:
iter = 0
print('iteration number: %d' % iter)
return b, alphas
Reference:
-
理解超平面
-
真正理解拉格朗日乘子法和KKT条件
-
拉格朗日对偶性
- 李航《统计学习方法–第二版》
- 周志华《机器学习》
写在最后:
实际上,这篇博客又有点虎头蛇尾的意思。。。如果真的对SVM感兴趣(特别是最后的SMO算法,我想我这里写的东西基本没人能看懂…)如果想弄懂的化建议可以机器学习和统计学习方法结合看。实际上,关于这部分的内容作者也差不多看了一个多星期的样子才没有那么迷惑,SVM还是一个很大的块,如果作者后面有想法可能会再次来更新这篇博客,写的更详细一些,包括文中没有写的软间隔(文中写的SVM是硬间隔)以及核函数等(实际上,这些是很重要的)。