阅读目标:
最近端午放假闲来无事,最近也在学习Linux ,因此想读读书,于是乎找到了这本《鸟哥 Linux 私房菜:基础版》进行阅读,在此我写下笔记记录这次阅读。每章的总结我只写下我认为最有意义的部分。
阅读总结:
第零章:
精简指令集:这种 CPU
的设计中,微指令集较为精简,每个指令的执行时间都很短,完成的动作也很单 纯,指令的执行性能较佳; 但是若要做复杂的事情,就要由多个指令来完成。常见的 RISC 微指令集 CPU
主要例如甲骨文 (
Oracle
) 公司的
SPARC
系列、 IBM 公司的
Power Architecture (包括
PowerPC
) 系列、与安谋公司 (
ARM Holdings
) 的
ARM CPU
系列等。
复杂指令集:与RISC不同的,
CISC
在微指令集的每个小指令可以执行一些较低阶的硬件操作,指令数目多 而且复杂, 每条指令的长度并不相同。因为指令执行较为复杂所以每条指令花费的时间较 长, 但每条个别指令可以处理的工作较为丰富。常见的CISC
微指令集
CPU
主要有
AMD
、 intel、
VIA
等的
x86
架构的
CPU
。
位:
所谓的位指的是CPU
一次数据读取的最大量!
64
位
CPU
代表
CPU
一次可以读写
64bits
这 么多的数据,32
位
CPU
则是
CPU
一次只能读取
32
位的意思。 因为CPU
读取数据量有限制,因此能够从内存中读写的数据也就有所限制。所以,一般32
位的
CPU
所能读写的最大数据量,大概就是4GB
左右。
内存变小问题:假设你今天购买了500GB
的硬盘一颗,但是格式化完毕后却只剩下
460GB
左右的容 量,这是什么原因?答:因为一般硬盘制造商会使用十进制的单位,所以500GByte
代表为 500
1000
1000*1000Byte
之意。
内频:
频 率就是CPU
每秒钟可以进行的工作次数。 所以频率越高表示这颗CPU
单位时间内可以作更多 的事情。举例来说Intel的
i7-4790 CPU
频率为
3.6GHz
, 表示这颗CPU
在一秒内可以进行 3.6×109次工作,每次工作都可以进行少数的指令运行之意。
外频:
外频指的是CPU
与外部元件进行数据传输时的速度。
超频:
将CPU
的倍频或者是外频通过主板的设置功能更改成较高频率的一种方式。
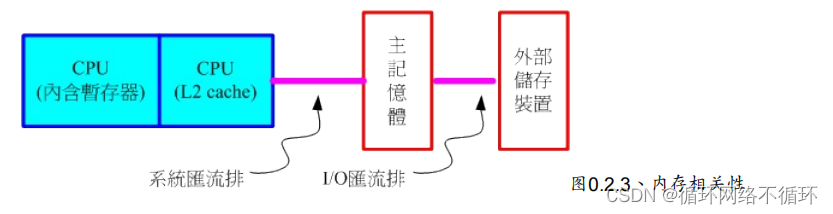
高速缓存原理图:
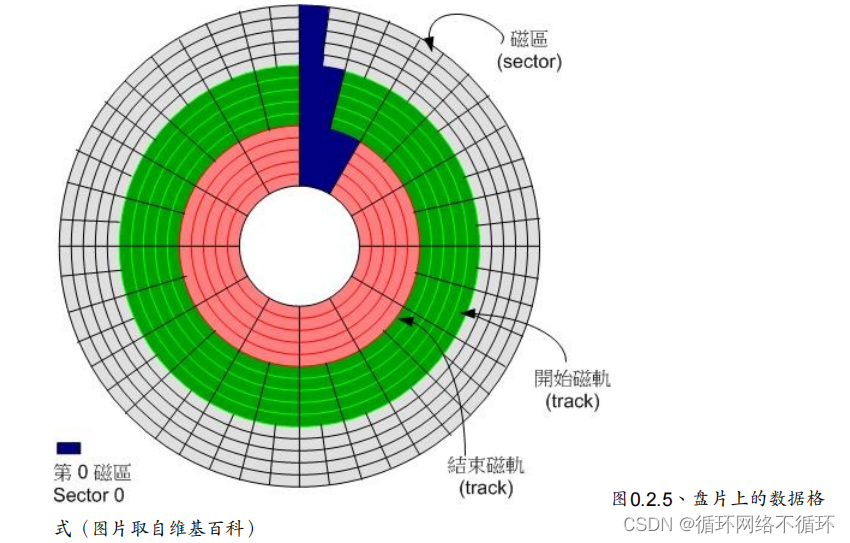
磁盘示意图:
IRQ:如果I/O位址想成是各设备的门牌号码的话,那么
IRQ
就可以想成是各个门牌连接到邮件中心 (CPU
)的专门路径。
第一章:
Linux 创始人最初在发布Linux 时发布的第一则公告:
Hello everybody out there using minix-
I’m doing a
(
free
)
operation system
(
just a hobby,
won’t be big and professional like gnu
)
for 386
(
486
)
AT clones.
I’ve currently ported bash
(
1.08
)
and gcc
(
1.40
)
,
and things seem to work. This implies that i’ll get
something practical within a few months, and I’d like to know
what features most people want. Any suggestions are welcome,
but I won’t promise I’ll implement them :-
)
第二章:
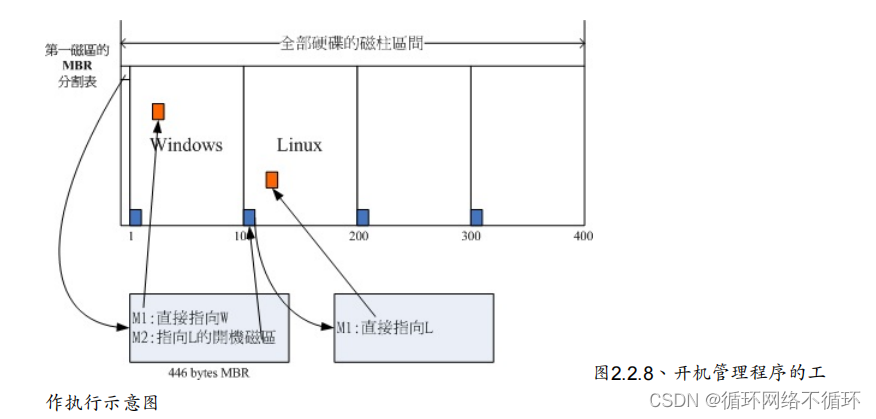
其实你刚刚拿到的整颗硬盘就像一根原木,你必须要在这根原木上面切割出你想要的区段, 这个区段才能够再制作成为你想要的家具!如果没有进行切割,那么原木就不能被有效的使用。
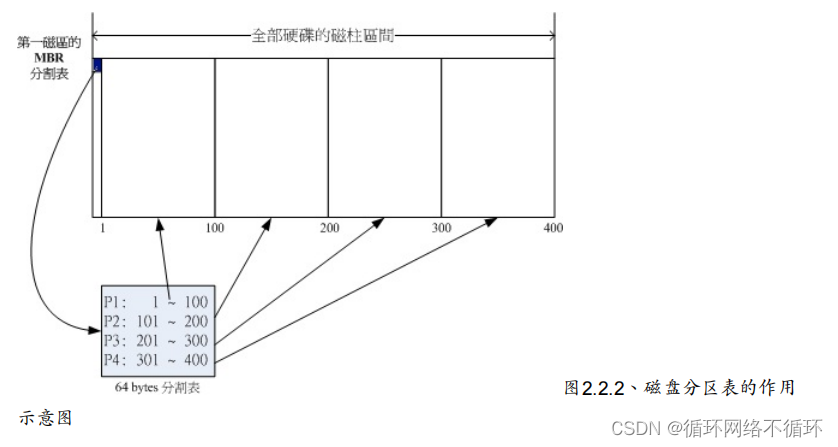
分区的意义:
1. 数据的安全性: 因为每个分区的数据是分开的!所以,当你需要将某个分区的数据重整 时,例如你要将计算机中Windows
的
C
盘重新安装一次系统时, 可以将其他重要数据移动到其他分区,例如将邮件、桌面数据移动到D
盘去,那么
C
盘重灌系统并不会影响到
D盘!所以善用分区,可以让你的数据更安全。 2. 系统的性能考虑:由于分区将数据集中在某个柱面的区段,例如上图当中第一个分区位于柱面号码1~100
号,如此一来当有数据要读取自该分区时,磁盘只会搜寻前面1~100
的柱面范围,由于数据集中了,将有助于数据读取的速度与性能!所以说,分区是很重要的!
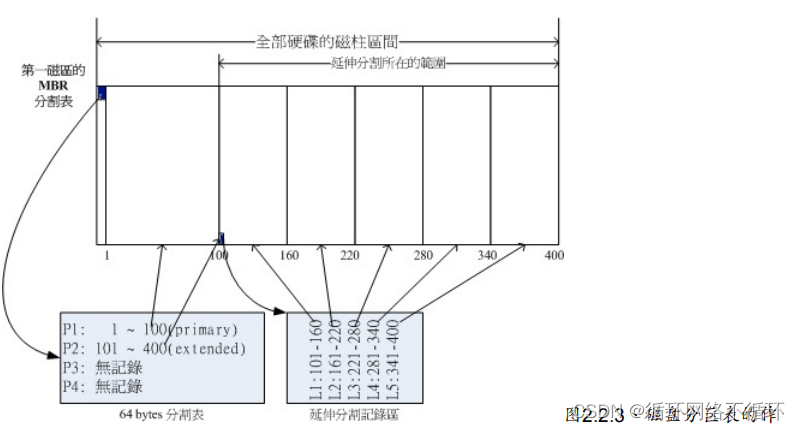
复杂分区示意图:
GPT
分区表的结构示意图:
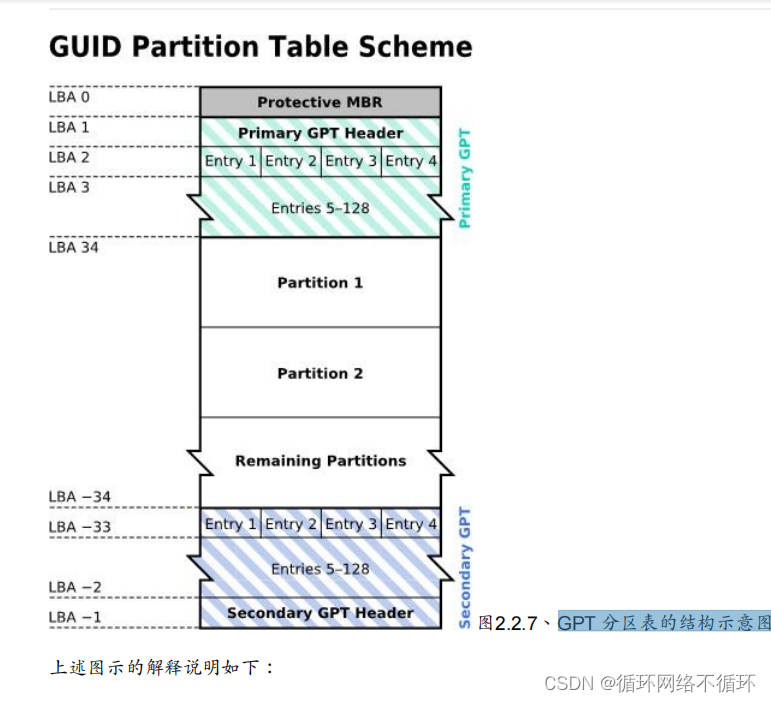
挂载:
所谓的“挂载”就是利用一个目录当成进入点,将磁盘分区的数据放置在该目录下;
也就是 说,进入该目录就可以读取该分区的意思。这个动作我们称为“
挂载
”
,那个进入点的目录我们 称为“
挂载点
”
。
第三章:
本章主要介绍
CentOS 7的安装,没有什么好介绍的。
第四章:
正确的关机指令使用: shutdown 与
reboot
两个指令!
第五章:
基本上,Linux
的文件是没有所谓的
“
扩展名
”
的,我们刚刚就谈过,一个
Linux
文件能不能被执
行,与他的第一栏的十个属性有关, 与文件名根本一点关系也没有。
很多读者都会误会
/usr
为
user
的缩写,其实
usr
是
Unix Software Resource
的缩写。
第六章:
pwd
:显示目前的目录
。
cat
是
Concatenate
(连续) 的简写。
鸟哥个人是比较少用 cat
啦!毕竟当你的文件内容的行数超过
40
行以上,嘿嘿!根本来不及
在屏幕上看到结果! 所以,配合等一下要介绍的 more
或者是
less 来执行比较好!
第七章:
为什么需要进行“格式化
”
呢?这是因为每种操作系统所设置的文件属性
/
权限并不相同,为了存放这些文件所需的数据,因此就需要将分区进行格式化,以成为操作系统能够利用的“
文件系统格式(filesystem)
”
。
inode/block
数据存取示意图:
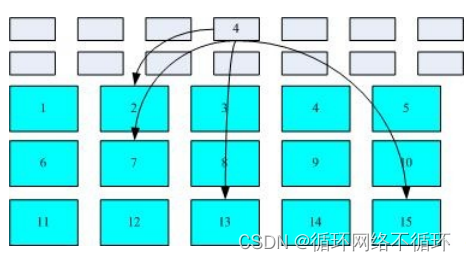
FAT 格式:

ext2文件系统示意图
:
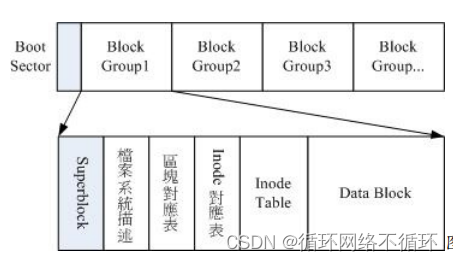
一般来说,我们将 inode table
与
data block
称为数据存放区域,至于其他例如
superblock
、
block bitmap
与
inode bitmap
等区段就被称为
metadata
(中介数据),因为
superblock,
inode bitmap
及
block bitmap
的数据是经常变动的,每次新增、移除、编辑时都可能会影响
到这三个部分的数据,因此才被称为中介数据的啦。
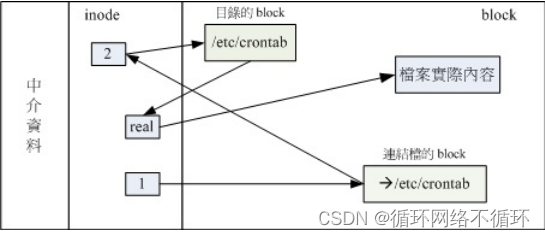
实体链接的文件读:

符号链接的文件读 取示意图:
swap:以前的年代因为内存不足,因此那个可以暂时将内存的程序拿到硬盘中暂放的内存交换空间 (swap) 就显的非常的重要! swap
主要的功能是当实体内存不够时,则某些在内存当中所占的程序会暂时被移动到 swap 当中,让实体内存可以被需要的程序来使用。
第八章:
由于我们记录数字是 1
,考虑计算机所谓的二进制喔,如此一来,1 会在最右边占据
1
个
bit
,而其他的
7
个
bits
将会自动的被填上
0
啰!你看看,其实在这样的例子中,那
7
个
bits
应该是“
空的
”
才对!不过,为了要满足目前我们的操作系统数据的存取,所以就会将该数据转为Byte 的型态来记录了!而一些聪明的计算机工程师就利用一些复杂的计算方式, 将这些没有使用到的空“
丢
”
出来,以让文件占用的空间变小!这就是压缩的技术啦! 另外一种压缩技术也很有趣,他是将重复的数据进行统计记录的。举例来说,如果你的数据为“111….”
共有
100
个
1
时,那么压缩技术会记录为“100
个
1”
而不是真的有
100
个
1
的位存在!这样也能够精简文件记录的容量呢!非常有趣吧!
第九章:
第十章:
在
Linux
的环境下,如果你不懂
bash
是什么,那么其他的东西就不用学了!
双引号内的特殊字符如 $
等,可以保有原本的特性,如下所示: “var=”lang is
$LANG””
则
“echo $var”
可得
“lang is zh_TW.UTF-8”。
第十一章:
第十二章:
第十三章:
第十四章:
soft, hard, grace time
的相关性:

LVM 的全名是
Logical Volume Manager
,中文可以翻译作逻辑卷轴管理员。之所以称为
“
卷
轴
”
可能是因为可以将
filesystem
像卷轴一样伸长或缩短之故吧!
LVM
的作法是将几个实体的
partitions
(或
disk
) 通过软件组合成为一块看起来是独立的大磁盘 (
VG
) ,然后将这块大
磁盘再经过分区成为可使用分区 (LV), 最终就能够挂载使用了。
第十五章:
其实 batch
是利用
at
来进行指令的下达啦!只是加入一些控制参数而已。这个
batch
神奇的
地方在于:他会在
CPU
的工作负载小于
0.8
的时候,才进行你所下达的工作任务啦! 那什么 是工作负载 0.8 呢?这个工作负载的意思是: CPU 在单一时间点所负责的工作数量。不是
仅执行一次的工作调度
CPU
的使用率喔! 举例来说,如果我有一只程序他需要一直使用 CPU
的运算能,那么此时 CPU
的使用率可能到达
100%
,但是 CPU
的工作负载则是趋近于
“ 1 ”
,因为
CPU
仅负
责一个工作嘛!如果同时执行这样的程序两支呢?
CPU
的使用率还是
100%
,但是工作负载
则变成
2
了!了解乎?所以也就是说,当 CPU
的工作负载越大,代表
CPU
必须要在不同的工作之间进行频繁的工作切换。这样的 CPU
运行情况我们在第零章有谈过,忘记的话请回去瞧瞧!因为一直切换工作,所以会导致系统忙碌啊!系统如果很忙碌,还要额外进行 at
,不太合理!所以才有batch 指令的产生!
第十六章:
老实说, Linux 几乎可以说绝对不会死机的!因为他可以在任 何时候, 将某个被困住的程序杀掉,然后再重新执行该程序而不用重新开机。
这个 PRI
值越低代表越优先的意思。
如果 I/O
部分很忙碌的话,你的系统会变的非常慢!
第十七章:
简单的说,系统为了某些功能必须要提供一些服务 (不论是系统本身还是网络方面),这个
服务就称为
service
。但是 service
的提供总是需要程序的运行吧!否则如何执行呢?所以达成这个 service
的程序我们就称呼他为
daemon
啰!举例来说,达成循环型例行性工作调度 服务 (service) 的程序为
crond
这个
daemon
啦!
第十八章:
第十九章:
第二十章:
第二十一章:
因为
Linux
上面的软件几乎都是经过
GPL
的授权,所以每个软件几乎均提供原始程序码, 并且你可以自行修改该程序码,以符合你个人的 需求呢!
利用这个特性,我们可以使用 MD5/sha1
或更严密的
sha256
等指纹验证机制来判断该文件有没有被更动过!
第二十二章:
RPM 全名是
“ RedHat Package Manager ”
简称则为
RPM。
评价:
本书比较基础,适合入门Linux的小伙伴阅读,如果有了一定开发经验的小伙伴就不建议阅读了,因为这本书太基础了。如果开发中想了解Linux我建议还是去菜鸡教程看,这本书有点啰嗦了。