Hadoop安装部署
1、实验描述
- 在若干节点中,安装部署hadoop分布式集群
2、实验环境
- 虚拟机数量:3
- 系统版本:Centos 7.5
- Hadoop版本: Apache Hadoop 2.7.3
3、相关技能
- 熟悉Linux操作系统
- Hadoop原理
4、知识点
- linux系统基础配置
- 配置JDK
- 配置hadoop的相关配置文件
- 掌握hadoop操作指令
5、效果图
hadoop集群安装部署后,启动集群,效果如下:
- 效果图1:master节点上,这4个进程表示主节点进程启动成功。

图 1
- 效果图2:slave01节点上出现了这3个进程表示从节点进程启动成功。

图 2
- 效果图3:slave02节点上出现了这3个进程表示从节点进程启动成功。

图 3
6、实验步骤
6.1登录大数据实验室,进入实验,(界面显示为master、slave01、slave02)
图 4
6.2确保各台虚拟机能ping通外网(上图界面中master、slave01、slave02,分别对应一个虚拟机,随后简称为“界面各虚拟机”)
6.2.1打开一个终端(下图根据centos7所使用的桌面系统不同会稍有区别,一般使用gnome或xfce)
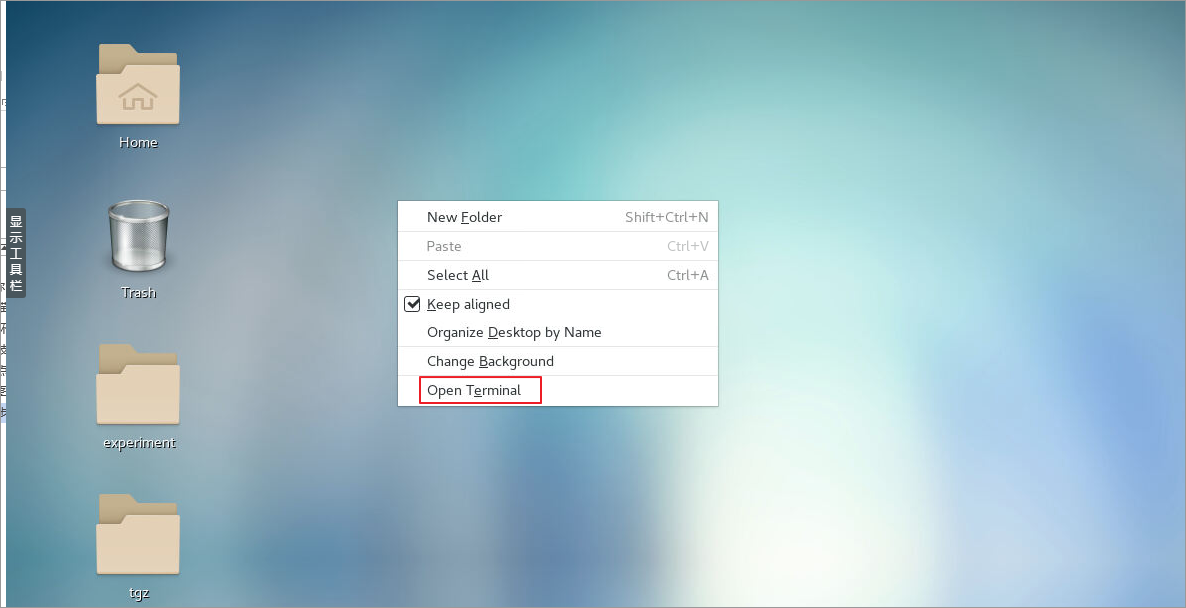
图 5
6.2.2ping一个外网网址,确保能够ping通,ctrl + c结束ping命令的执行(大数据实验室提供的虚拟机默认已可ping通外网)
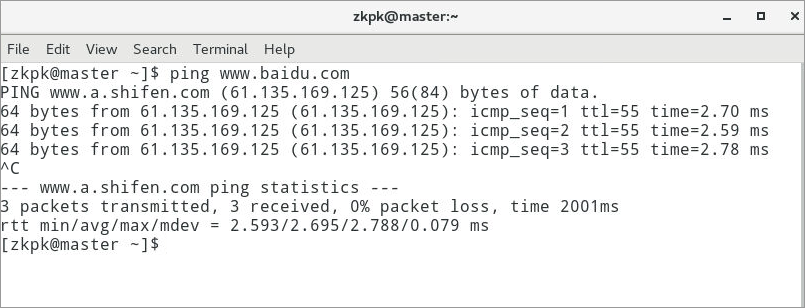
图 6
6.3配置主机名(“界面各虚拟机”分别操作此步骤,主机名分别设置为master, slave01,slave02)
说明:此处以界面虚拟机master的操作为例(本实验中大数据实验室的机器默认已经配置好主机名称,这里只需要确认其是否正确即可)
6.3.1以下操作需要root权限,所以先切换成root用户,密码:zkpk
[zkpk@localhost ~]$ su root

图 7
6.3.2使用gedit编辑主机名(或使用vim)
6.3.2.1编辑主机名文件
[root@localhost ~]# gedit /etc/hostname
6.3.2.2将原来内容替换为master
master
6.3.2.3保存并退出
6.3.2.4临时设置主机名为master:
[root@localhost ~]# hostname master
6.3.2.5检测主机名是否修改成功:
说明:bash命令让上一步操作生效
[root@localhost zkpk]# bash[root@master zkpk]# hostnamemaster

图 8
6.4配置时钟同步(使用root权限;“界面各虚拟机”分别操作此步骤;若已配置过,请忽略此步骤)
说明:此处以master节点的操作为例
6.4.1配置自动时钟同步
6.4.1.1使用Linux命令配置
[root@master zkpk]# crontab -e
6.4.1.2按”i ”键,进入插入模式;输入下面的内容(星号之间和前后都有空格)
0 1 * * * /usr/sbin/ntpdate cn.pool.ntp.org
6.4.1.3按Esc退出插入模式,然后按”: ”键,输入wq保存退出
6.4.2手动同步时间,直接在Terminal运行下面的命令:
[root@master zkpk]# /usr/sbin/ntpdate cn.pool.ntp.org
6.5关闭防火墙(使用root权限;“界面各虚拟机”分别操作此步骤;若已配置过,请忽略此步骤)
6.5.1查看防火墙状态(默认已经关闭防火墙)
[root@master ~]# systemctl status firewalld.service

图 9
6.5.2在终端中执行下面命令:
说明:两条命令分别是临时关闭防火墙和禁止开机启动防火墙
[root@master ~]# systemctl stop firewalld.service[root@master ~]# systemctl disable firewalld.service
6.6配置hosts列表(使用root权限;“界面各虚拟机”分别操作此步骤;默认已经配置)
6.6.1先分别在各虚拟机中运行ifconfig命令,获得当前节点的ip地址,如下图是master的ip地址
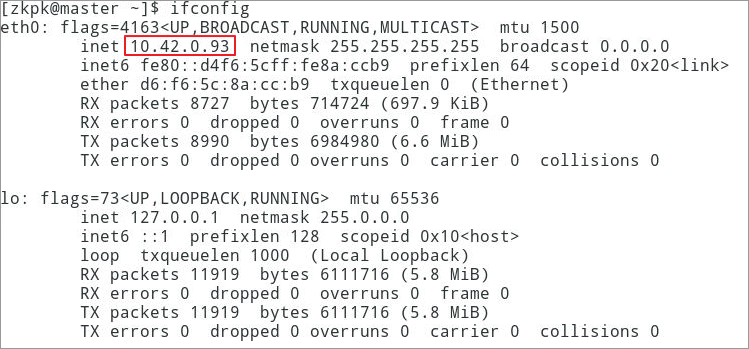
图 10
6.6.2编辑主机名列表文件:
[root@master zkpk]# vi /etc/hosts
6.6.3将下面三行添加到/etc/hosts文件中,保存退出:
注意:这里是假设master节点对应IP地址是10.42.0.93,slave01对应的IP是10.42.0.94,slave02对应的IP是10.42.0.95,而自己在做配置时,需要将IP地址改成自己的master、slave01和slave02对应的IP地址。而在大数据实验室中我们的程序已经自动为我们配置好了所有机器的hosts文件,这里我们只需要打开确认其是否正确即可
10.42.0.93 master10.42.0.94 slave0110.42.0.95 slave02
6.6.4Ping主机名
[root@master ~]# ping master -c 3[root@master ~]# ping slave01 -c 3 [root@master ~]# ping slave02 -c 3
6.6.5如果出现下图的信息表示配置成功:
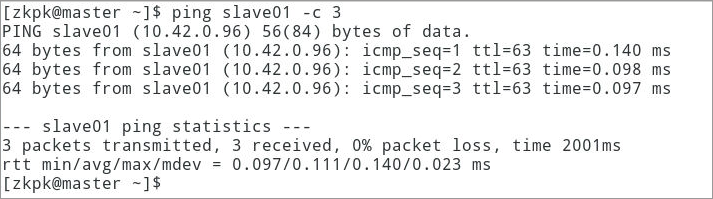
图 11
6.7免密钥登录配置(注意:使用zkpk用户)
6.7.1master节点上
6.7.1.1先从root用户,退回到普通用户zkpk
[root@master ~]$ su zkpk[zkpk@master ~]$
6.7.1.2在终端生成密钥,命令如下(一路按回车完成密钥生成)
[zkpk@master ~]$ ssh-keygen -t rsa
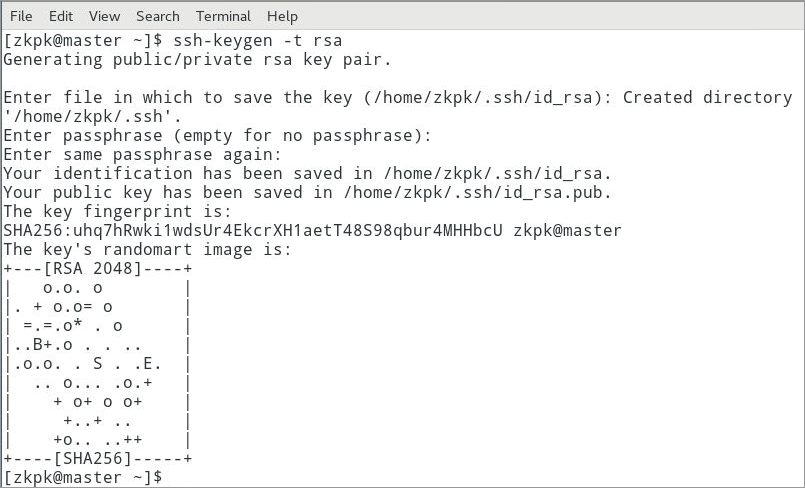
图 12
6.7.1.3生成的密钥在用户根目录中的.ssh子目录中,进入.ssh目录,如下图操作:

图 13
6.7.1.4进行复制公钥文件
[zkpk@master .ssh]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
6.7.1.5执行ls -l命令后会看到下图的文件列表:

图 14
6.7.1.6修改authorized_keys文件的权限,命令如下:
[zkpk@master .ssh]$ chmod 600 ~/.ssh/authorized_keys
6.7.1.7将专用密钥添加到 ssh-agent 的高速缓存中
[zkpk@master .ssh]$ ssh-add ~/.ssh/id_rsa
6.7.1.8将authorized_keys文件复制到slave01、slave02节点zkpk用户的根目录,命令如下:
说明:如果提示输入yes/no的时候,输入yes,回车。密码是:zkpk
[zkpk@master .ssh]$ scp ~/.ssh/authorized_keys zkpk@slave01:~/[zkpk@master .ssh]$ scp ~/.ssh/authorized_keys zkpk@slave02:~/
6.7.2slave01节点
6.7.2.1在终端生成密钥,命令如下(一路点击回车生成密钥)
[zkpk@slave01 ~]$ ssh-keygen -t rsa
6.7.2.2将authorized_keys文件移动到.ssh目录
[zkpk@slave01 ~]$ mv authorized_keys ~/.ssh/
6.7.3slave02节点
6.7.3.1在终端生成密钥,命令如下(一路点击回车生成密钥)
[zkpk@slave02 ~]$ ssh-keygen -t rsa
6.7.3.2将authorized_keys文件移动到.ssh目录
[zkpk@slave02 ~]$ mv authorized_keys ~/.ssh/
6.7.4验证免密钥登陆
6.7.4.1在master机器上远程登录slave01:
[zkpk@master ~]$ ssh slave01
6.7.4.2如果出现下图的内容表示免密钥配置成功:

图 15
6.7.4.3退出slave01远程登录
[zkpk@slave01 ~]$ exit[zkpk@master ~]$
6.7.4.4在master机器上远程登录slave02:
[zkpk@master ~]$ ssh slave02
6.7.4.5如果出现下图的内容表示免密钥配置成功:

图 16
6.8安装JDK(在三台节点分别操作此步骤)
6.8.1删除系统自带的jdk(如若出现下图效果,说明系统自带java,需要先卸载)
6.8.1.1查看系统自带jdk
[zkpk@master ~]$ rpm -qa | grep java

图 17
6.8.1.2切换root用户,密码:zkpk
[zkpk@master ~]$ su root
6.8.1.3移除系统自带的jdk
[root@master zkpk]# yum remove java-1.*
6.8.1.4创建存放jdk文件目录
[root@master zkpk]# mkdir /usr/java
6.8.2将/home/zkpk/tgz下的JDK压缩包解压到/usr/java目录下
[root@master zkpk]# tar -xzvf /home/zkpk/tgz/jdk-8u131-linux-x64.tar.gz -C /usr/java
6.8.2.1退出root用户
[root@master zkpk]# exit
6.8.3配置zkpk用户环境变量
6.8.3.1使用gedit修改“.bash_profile”
[zkpk@master ~]$ gedit /home/zkpk/.bash_profile
6.8.3.2复制粘贴以下内容添加到到上面gedit打开的文件中:
export JAVA_HOME=/usr/java/jdk1.8.0_131/export PATH=$JAVA_HOME/bin:$PATH
6.8.4使环境变量生效:
[zkpk@master ~]$ source /home/zkpk/.bash_profile
6.8.5查看java是否配置成功:
[zkpk@master ~]$ java -version

图 18
6.9安装部署Hadoop集群(zkpk用户)
说明:每个节点上的Hadoop配置基本相同,在master节点操作,然后复制到slave01、slave02两个节点。
6.9.1将/home/zkpk/tgz/hadoop目录下的Hadoop压缩包解压到/home/zkpk目录下
[zkpk@master ~]$ tar -xzvf /home/zkpk/tgz/hadoop-2.7.3.tar.gz –C /home/zkpk
6.9.2配置hadoop-env.sh文件
6.9.2.1使用gedit命令修改hadoop-env.sh文件
[zkpk@master ~]$ gedit /home/zkpk/hadoop-2.7.3/etc/hadoop/hadoop-env.sh
6.9.2.2修改JAVA_HOME环境变量
export JAVA_HOME=/usr/java/jdk1.8.0_131/
6.9.3配置yarn-env.sh文件
6.9.3.1使用gedit命令修改yarn-env.sh文件
[zkpk@master ~]$ gedit ~/hadoop-2.7.3/etc/hadoop/yarn-env.sh
6.9.3.2修改JAVA_HOME环境变量
export JAVA_HOME=/usr/java/jdk1.8.0_131/
6.9.4配置core-site.xml 文件
6.9.4.1使用gedit命令修改core-site.xml文件
[zkpk@master ~]$ gedit ~/hadoop-2.7.3/etc/hadoop/core-site.xml
6.9.4.2用下面的代码替换core-site.xml中的内容:
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/zkpk/hadoopdata</value> </property></configuration>
6.9.5配置hdfs-site.xml文件
6.9.5.1使用gedit命令修改hdfs-site.xml文件
[zkpk@master ~]$ gedit ~/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
6.9.5.2用下面的代码替换hdfs-site.xml中的内容:
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration> <property> <name>dfs.replication</name> <value>2</value> </property></configuration>
6.9.6配置yarn-site.xml文件
6.9.6.1使用gedit命令修改yarn-site.xml文件
[zkpk@master ~]$ gedit ~/hadoop-2.7.3/etc/hadoop/yarn-site.xml
6.9.6.2用下面的代码替换yarn-site.xml中的内容:
<?xml version="1.0"?><configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:18040</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:18030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:18025</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:18141</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:18088</value> </property></configuration>
6.9.7配置mapred-site.xml文件
6.9.7.1复制mapred-site-template.xml文件:
[zkpk@master ~]$ cp ~/hadoop-2.7.3/etc/hadoop/mapred-site.xml.template ~/hadoop-2.7.3/etc/hadoop/mapred-site.xml
6.9.7.2使用gedit编辑mapred-site.xml文件:
[zkpk@master ~]$ gedit ~/hadoop-2.7.3/etc/hadoop/mapred-site.xml
6.9.7.3用下面的代码替换mapred-site.xml中的内容
<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property></configuration>
6.9.8配置slaves文件
6.9.8.1使用gedit编辑slaves文件:
[zkpk@master ~]$ gedit ~/hadoop-2.7.3/etc/hadoop/slaves
6.9.8.2将slaves中的内容用如下代码替换
slave01slave02
6.9.9创建Hadoop数据目录
[zkpk@master ~]$ cd [zkpk@master ~]$ mkdir hadoopdata
6.9.10将配置好的hadoop文件夹复制到从节点
6.9.10.1使用scp命令将文件夹复制到slave01、slave02上:
说明:因为之前已经配置了免密钥登录,这里可以直接免密钥远程复制。
[zkpk@master ~]$ scp -r hadoop-2.7.3 zkpk@slave01:~/[zkpk@master ~]$ scp -r hadoop-2.7.3 zkpk@slave02:~/
6.10配置Hadoop环境变量(在三台节点分别操作此步骤,zkpk用户)
6.10.1以master节点为例
[zkpk@master ~]$ gedit ~/.bash_profile
6.10.2在.bash_profile末尾添加如下内容:
#HADOOPexport HADOOP_HOME=/home/zkpk/hadoop-2.7.3export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
6.10.3使环境变量生效:
[zkpk@master ~]$ source ~/.bash_profile
6.11格式化Hadoop文件目录(在master上执行)
6.11.1格式化命令如下
[zkpk@master ~]$ hdfs namenode -format
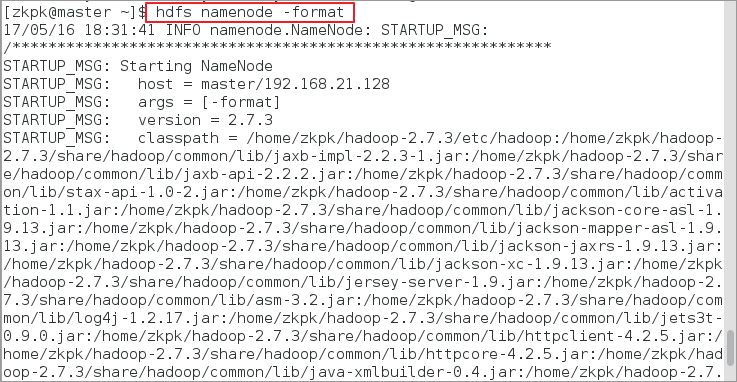
图 19
6.12启动Hadoop集群(在master上执行)
6.12.1运行start-all.sh命令
说明:格式化后首次执行此命令,提示输入yes/no时,输入yes。
[zkpk@master ~]$ start-all.sh
6.12.2查看进程是否启动
6.12.2.1在master的终端执行jps命令,出现下图效果

图 20
6.12.2.2在slave01的终端执行jps命令,出现如下效果

图 21
6.12.2.3在slave02的终端执行jps命令,出现如下效果

图 22
6.12.3Web UI查看集群是否成功启动
6.12.3.1在master上打开Firefox浏览器,在浏览器地址栏中输入http://master:50070/,检查namenode 和datanode 是否正常,如下图所示。
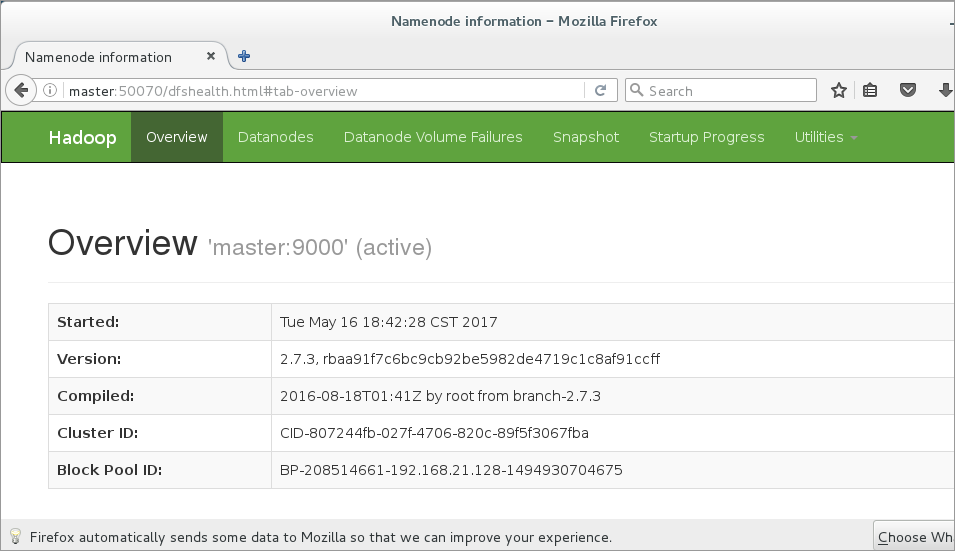
图 23
6.12.3.2打开浏览器新标签页,地址栏中输入http://master:18088/,检查Yarn是否正常,如下图所示。

图 24
6.12.4运行PI实例检查集群是否成功
6.12.4.1执行下面的命令:
[zkpk@master~]$ hadoop jar ~/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar pi 10 10
6.12.4.2会看到如下的执行结果:
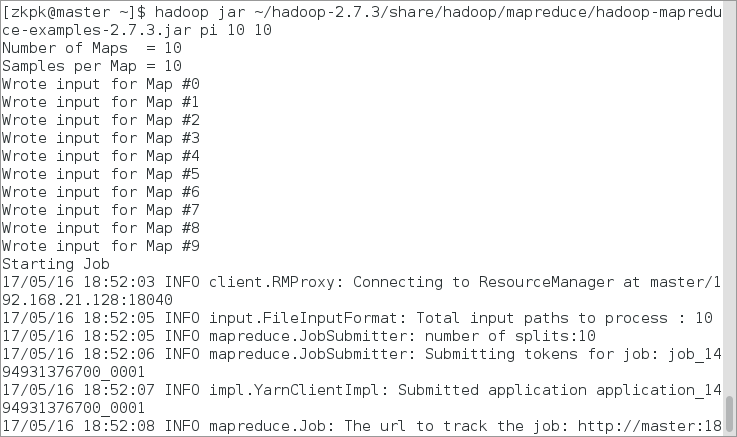
图 25
6.12.4.3最后输出:Estimated value of Pi is 3.20000000000000000000
说明:如果出现以上3个验证步骤图片结果,集群正常启动。
7、总结
搭建Hadoop集群,需要熟悉对linux系统操作,并且每一步骤要细心检查确保无误,这样在部署的时候会比较顺利一点。