文章目录
0. 写在前面
- 这篇文章发表在2016年,算是比较早的文章,但很值得去看,算法深度无监督聚类的一个经典文章,本博客从模型、LOSS来讲,实验部分不着重讲。
1. 摘要
摘要部分,作者主要告诉我们
DEC模型的聚类不是从数据本身来聚类,而是学习到数据到隐空间的映射,然后设置了聚类优化目标来学习隐空间的聚类
,该模型不是生成模型,类似于K-means,选取了聚类中心,然后让数据自动逼近自己所属的聚类中心。

2. 介绍
这部分主要讲明该模型的三大贡献
(a)深度嵌入和聚类的联合优化;
(b)通过软分配进行新颖的迭代改进;
(c)得出聚类精度和速度方面最先进的聚类结果;

3. 相关工作
这部分不太重要,略读

4. DEC模型
-
作者对模型行的
训练分为两个部分
1.用AE进行
参数初始化
,这一步和VaDE的预训练很像,是为了让模型在初始化时就学习到良好的隐空间表示。对于聚类中心的初始化,作者在隐空间中使用标准的K-means方法。
2.用KL散度作为LOSS进行
优化参数
,参数包括两部分{θ,μ},θ是encoder的神经网络参数,μ是聚类中心 -
看图说话,第一张图是原著,第二张图是其他论文中画的,两者异曲同工。
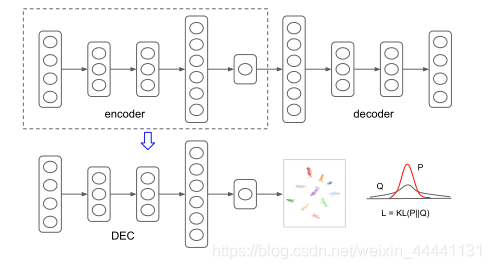
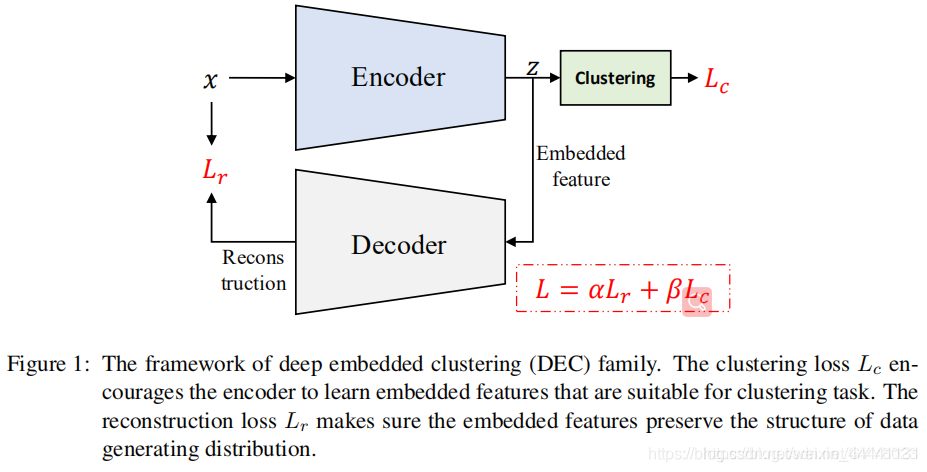
4.1 用KL散度进行聚类
作者先从训练过程的第二个阶段开始讲,这个过程又被分成两步:
1.计算隐空间的数据点和聚类中心的“软概率分布”
2.通过一个辅助的分布来计算KL散度作为LOSS以此来更新参数

4.1.1 软概率分布
在这里,作者使用了t-分布,也叫学生分布来衡量隐空间的数据点z和聚类中心的相似度(similarity)。t-分布我们很熟悉,就是一个统计量服从分子是标准正态分布,分母是卡方分布的一个分布。qij指的就是对于第i个样本,它和第j个聚类中心的相似度。

4.1.2 辅助分布
关于辅助分布,作者认为这对模型的效果是至关重要的,他必须满足下面三个条件:

所以作者选择了如下的分布,关于这一点,我不太清楚作者这么选择的更多的理由,可能是知识储备不够吧。

4.1.3 优化
优化方法就很常见的神经网络优化方法,需要注意的是,迭代终止条件是:
低于 tol%的样本不再改变聚类的选择时,停止训练。

4.2 参数初始化
- 从模型结构图来看,它使用了AE进行参数初始话,均值采用的是K-means方法


5. 实验
关于实验我只想讲一点,就是梯度与概率分配的关系,这很重要。
-
对于某个隐空间的点z,当他倾向于归属某一类时,LOSS在这一点的梯度回很大,相反对于其他类梯度就会很小。这说明模型捕捉到了z的聚类效果。


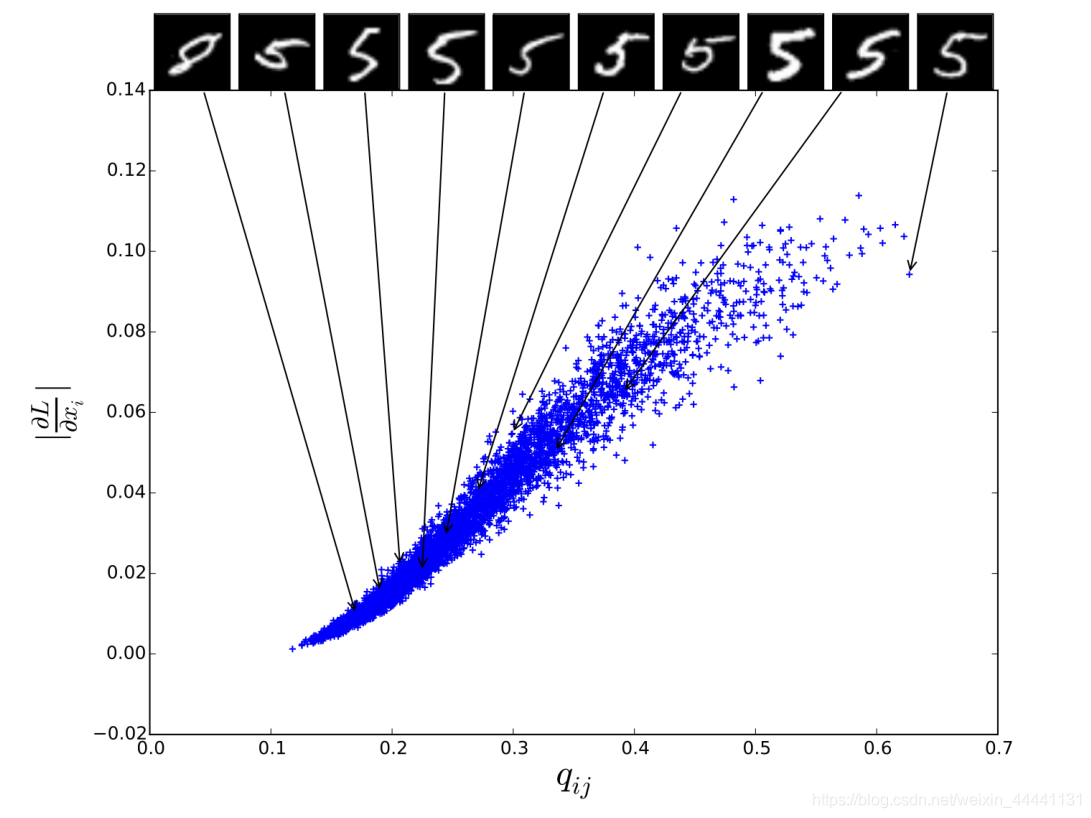
6. 结论
这里就总结了以下DEC模型的结构、LOSS、和实验结果。
