本文地址:
http://blog.csdn.net/mounty_fsc/article/details/51746111
《Network in Network》论文笔记
1.综述
这篇文章有两个很重要的观点:
-
1×1卷积的使用
文中提出使用mlpconv网络层替代传统的convolution层。mlp层实际上是卷积加传统的mlp(多层感知器),因为convolution是线性的,而mlp是非线性的,后者能够得到更高的抽象,泛化能力更强。在跨通道(cross channel,cross feature map)情况下,mlpconv等价于卷积层+1×1卷积层,所以此时mlpconv层也叫cccp层(cascaded cross channel parametric pooling)。 -
CNN网络中不使用FC层(全连接层)
文中提出使用Global Average Pooling取代最后的全连接层,因为全连接层参数多且易过拟合。做法即移除全连接层,在最后一层(文中使用mlpconv)层,后面加一层Average Pooling层。
以上两点,之所以重要,在于,其在较大程度上减少了参数个数,确能够得到一个较好的结果。而参数规模的减少,不仅有利用网络层数的加深(由于参数过多,网络规模过大,GPU显存等不够用而限制网络层数的增加,从而限制模型的泛化能力),而且在训练时间上也得到改进。
2.网络结构
-
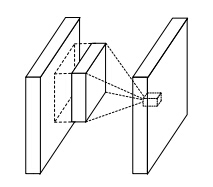
传统的convolution层
-
单通道mlpconv层
-
跨通道mlpconv层(cccp层)
-
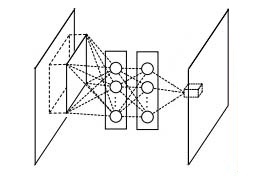
由图可知,mlpconv=convolution+mlp(图中为2层的mlp)。
-
在caffe中实现上,mlpconv=convolution+1×1convolution+1×1convolution(2层的mlp)
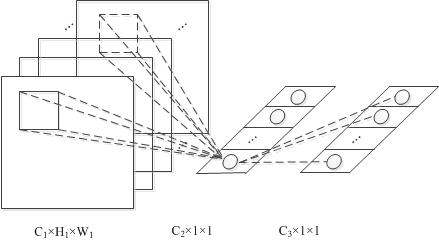
3.Caffe中的实现
原文3层mlpconv的完整网络结构
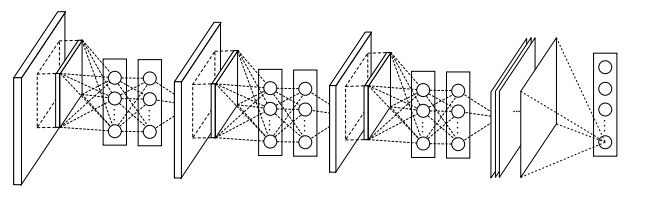
Caffe中4层网络示意图(ImageNet)
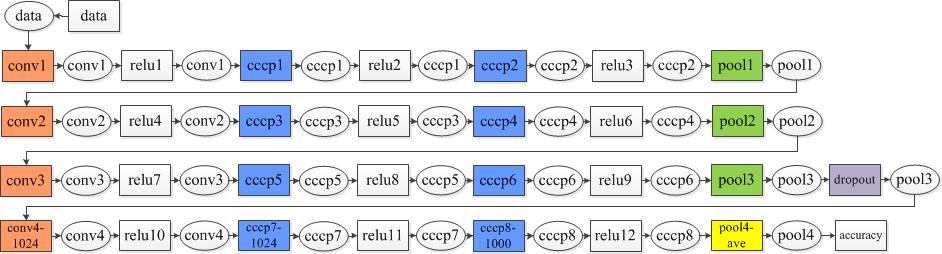
说明:
1.方框为网络层,椭圆为blob
2.黄色pool4为Average Pooling
caffe网络数据数据如下(crop size=224)
| Layer | channels | Filter size | Filter stride | Padding size | Input size |
|---|---|---|---|---|---|
| conv1 | 96 | 11 | 4 | – | 224×224 |
| cccp1 | 96 | 1 | 1 | – | 54×54 |
| cccp2 | 96 | 1 | 1 | – | 54×54 |
| pool1 | 96 | 3 | 2 | – | 54×54 |
| conv2 | 256 | 5 | 1 | 2 | 27×27 |
| cccp3 | 256 | 1 | 1 | – | 27×27 |
| cccp4 | 256 | 1 | 1 | – | 27×27 |
| pool2 | 256 | 3 | 2 | – | 27×27 |
| conv3 | 384 | 3 | 1 | 1 | 13×13 |
| cccp5 | 384 | 1 | 1 | – | 13×13 |
| cccp6 | 384 | 1 | 1 | – | 13×13 |
| pool3 | 384 | 3 | 2 | – | 13×13 |
| conv4-1024 | 1024 | 3 | 1 | 1 | 6×6 |
| cccp7-1024 | 1024 | 1 | 1 | – | 6×6 |
| cccp8-1000 | 1000 | 1 | 1 | – | 6×6 |
| pool4-ave | 1000 | 6 | 1 | – | 6×6 |
| accuracy | 1000 | – | – | – | 1×1 |
- 对于crop size = 227,则input size的变化为227, 55, 27, 13, 6, 1。
4. 1×1卷积的作用
以下内容摘抄自:
http://www.caffecn.cn/?/question/136
问:发现很多网络使用了1X1卷积核,这能起到什么作用呢?另外我一直觉得,1X1卷积核就是对输入的一个比例缩放,因为1X1卷积核只有一个参数,这个核在输入上滑动,就相当于给输入数据乘以一个系数。不知道我理解的是否正确
答1:
对于单通道的feature map和单个卷积核之间的卷积来说,题主的理解是对的,CNN里的卷积大都是多通道的feature map和多通道的卷积核之间的操作(输入的多通道的feature map和一组卷积核做卷积求和得到一个输出的feature map),如果使用1×1的卷积核,这个操作实现的就是多个feature map的线性组合,可以实现feature map在通道个数上的变化。接在普通的卷积层的后面,配合激活函数,就可以实现network in network的结构了(本内容作者仅授权给CaffeCN社区(caffecn.cn)使用,如需转载请附上内容来源说明。)
答2:
我来说说我的理解,我认为1×1的卷积大概有两个方面的作用吧:
1. 实现跨通道的交互和信息整合
2. 进行卷积核通道数的降维和升维
下面详细解释一下:
1. 这一点孙琳钧童鞋讲的很清楚。1×1的卷积层(可能)引起人们的重视是在NIN的结构中,论文中林敏师兄的想法是利用MLP代替传统的线性卷积核,从而提高网络的表达能力。文中同时利用了跨通道pooling的角度解释,认为文中提出的MLP其实等价于在传统卷积核后面接cccp层,从而实现多个feature map的线性组合,实现跨通道的信息整合。而cccp层是等价于1×1卷积的,因此细看NIN的caffe实现,就是在每个传统卷积层后面接了两个cccp层(其实就是接了两个1×1的卷积层)。
2. 进行降维和升维引起人们重视的(可能)是在GoogLeNet里。对于每一个Inception模块(如下图),原始模块是左图,右图中是加入了1×1卷积进行降维的。虽然左图的卷积核都比较小,但是当输入和输出的通道数很大时,乘起来也会使得卷积核参数变的很大,而右图加入1×1卷积后可以降低输入的通道数,卷积核参数、运算复杂度也就跟着降下来了。以GoogLeNet的3a模块为例,输入的feature map是28×28×192,3a模块中1×1卷积通道为64,3×3卷积通道为128,5×5卷积通道为32,如果是左图结构,那么卷积核参数为1×1×192×64+3×3×192×128+5×5×192×32,而右图对3×3和5×5卷积层前分别加入了通道数为96和16的1×1卷积层,这样卷积核参数就变成了1×1×192×64+(1×1×192×96+3×3×96×128)+(1×1×192×16+5×5×16×32),参数大约减少到原来的三分之一。同时在并行pooling层后面加入1×1卷积层后也可以降低输出的feature map数量,左图pooling后feature map是不变的,再加卷积层得到的feature map,会使输出的feature map扩大到416,如果每个模块都这样,网络的输出会越来越大。而右图在pooling后面加了通道为32的1×1卷积,使得输出的feature map数降到了256。GoogLeNet利用1×1的卷积降维后,得到了更为紧凑的网络结构,虽然总共有22层,但是参数数量却只是8层的AlexNet的十二分之一(当然也有很大一部分原因是去掉了全连接层)。

最近大热的MSRA的ResNet同样也利用了1×1卷积,并且是在3×3卷积层的前后都使用了,不仅进行了降维,还进行了升维,使得卷积层的输入和输出的通道数都减小,参数数量进一步减少,如下图的结构。(不然真不敢想象152层的网络要怎么跑起来TAT)

[1].
https://gist.github.com/mavenlin/d802a5849de39225bcc6
[2].
http://www.caffecn.cn/?/question/136