文章目录
一、数据类型介绍。
(1)C语言自带基本类型:
| 数据类型 | 意义 | 字节数 |
|---|---|---|
| char |
类型 |
字节 |
| short |
型 |
字节 |
| int |
型 |
字节 |
| long |
型 |
字节 或 字节 |
| long long |
型 |
字节 |
| float |
浮点数 |
字节 |
| double |
浮点数 |
字节 |
(2)类型的基本归类:
—————————-
整型类型:(只有整型分有符号和无符号)
———————–
char:
unsigned char
signed char
注:字符存储时,存储的是ASCII码值,是整型,所以认为char是整型。
直接写成 char 是 signed char 还是 unsigned char 是不确定的(取决于编译器)
short:
unsigned short [int]
signed short [int] = short [int]
注:( [int]通常会省略掉 )
int:
unsigned int
signed int = int
long:
unsigned long [int]
signed long [int] = long [int]
注:( [int]通常会省略掉 )
long long :
unsigned long long [int]
signed long long [int] = long long [int]
注:( [int]通常会省略掉 )
signed:二进制位的最高位是
符号位
,其它位都是
数值位
。
unsigned:二进制位的最高位也是
数值位
,即所有位都是
数值位
。
signed char 范围是:-128~127,补码:10000000无法转换为原码,被直接当成-128
unsigned char 范围是:0~255,8位全是
数值位
,无负数
———————————————
浮点数类型:
———————————————
float
double
long double
———————————————
构造类型(自定义类型):
——————————-
数组类型:
int arr1[50]; 类型是 int [50]
float arr2[100]; 类型是 float [100]
char arr3[20]; 类型是 char [20]
注:(这是三个不同的数组类型)
结构体类型 :
struct
枚举类型:
enumt
联合类型:
union
————————————————-
指针类型:
——————————————–
int*
pi;
char*
pc;
float*
pf;
void*
pv;
————————————————-
空类型:
——————————————–
void 表示 空类型(无类型):通常应用于
函数的返回类型、函数的参数、指针类型
。
类型的意义:
-
使用这个类型开辟
内存空间的大小
(
大小
决定了使用范围) -
用于存储整数值,可以进行算术运算。不同的整数类型在内存中占用的空间大小不同,可以根据需要选择合适的类型来
节省内存空间
。
例如:有些整型数据可能比较小,使用short就够了(short的范围:-32768 ~ 32767。)如:身高,年龄等。 -
字符类型(char):用于表示单个字符。字符类型可以用来存储
字母
、
数字
、
标点符号
等。 -
数组类型(array):用于存储一组相同类型的元素。数组可以按照
索引访问
和
操作
其中的元素。 -
指针类型(pointer):用于存储变量的内存地址。指针类型可以用于
实现动态内存分配、数据结构和函数指针
等。 -
结构体类型(struct):用于定义自定义的复合数据类型,可以包含
多个不同类型的成员变量
。 -
枚举类型(enum):用于定义一组具有名称的常量。枚举类型可以用于
增加代码的可读性和可维护性
。
二、 整型在内存中的存储
一个变量的创建是要在内存中开辟空间的,空间的大小是根据不同的类型而决定的
那么开辟空间后,数据在所开辟内存中是如何存储的呢?
1.原码、反码、补码(整数的三种二进制表示形式):
原码:
正数:直接将数值按照正负数的形式翻译成二进制得到原码
负数: (1)直接将数值按照正负数的形式翻译成二进制得到原码
(2)反码按位取反得到原码
(3)补码按位取反,再+1得到原码
反码:
正数:原码、反码、补码 都相同
负数:原码的符号位不变,将其它位依次按位取反得到反码
或者补码-1得到反码
补码:
正数:原码、反码、补码 都相同
负数:反码+1得到补码

代码如下(示例):
#include <stdio.h>
int main()
{
int a = 10;//创建一个值为10的整型变量a,这时a向内存申请4个字节来存放数据
// 4个字节 - 32比特位
//00000000000000000000000000001010 -- 原码
//00000000000000000000000000001010 -- 反码
//00000000000000000000000000001010 -- 补码
int b = -10;
//10000000000000000000000000001010 -- 原码
//11111111111111111111111111110101 -- 反码
//11111111111111111111111111110110 -- 补码
return 0;
}
对于整型来说:数据存放在内存中其实存放的是补码
在计算机系统中,数值一律用
补码
来表示和存储。
原因在于:使用补码,可以将
符号位
和
数值位
统一处理(把符号位也看成数值位来计算);
同时,
加法
和
减法
也可以统一处理(CPU只有
加法器
),
此外,
补码和原码相互转换,其运算过程是相同的
(原码转换为补码按位取反再+1,补码转换为原码也可以按位取反再+1),
不需要额外的硬件电路。

为什么会导致储存?
2.大小端介绍
(1)字节序:
以字节为单位,有
两种
存储顺序(
大端
字节序存储 /
小端
字节序存储)
(2)低位 / 高位:
十进制:
数字123,1是百位,2是十位,3是个位。这里的1就是高位,3就是低位。
十六进制:
0x 11 22 33 44,这里 11 就是
高位
,44就是
低位
。
(3)大端字节序存储:
大端(存储)模式:
指数据的
低位字节
内容保存在内存的
高地址
中,而数据的
高位字节
内容,保存在内存的
低地址
中。(
低位高地址,高位低地址
)
(4)小端字节序存储:
小端(存储)模式:
指数据的
低位字节
内容保存在内存的
低地址
中,而数据的
高位字节
内容,保存在内存的
高地址
中。(
低位低地址,高位高地址
)
为什么有大端和小段:
一个数据只要超过一个字节,在内存中存储的时候就必然涉及到顺序的问题
,所以要有大端和小端的存储模式
对该数据进行排序
。
为什么会有大小端模式之分,是因为在计算机系统中,我们是以
字节
为单位的,每个地址单元都对应着
一个字节
,一个字节为
8bit
。但是在C语言中除了 8bit 的 char 之外,还有
16bit 的 short 类型,32位的 long 类型(具体要看编译器)
,另外,对于
位数大于8位
的处理器,例如 16位 或者 32位 的处理器,由于寄存器宽度
大于
一个字节,那么就存在着一个如何将多个字节安排的问题。因此就导致了
大端存储模式和小端存储模式
。
例如:一个
16bit
的
short
类型 x ,在内存中的地址为
0x0010
,x 的值为
0x1122
,那么
0x11
为
高
字节,
0x22
为
低
字节。对于
大端
模式,就将
0x11
放在
低
地址中,即地址
0x0010
中,
0x22
放在
高
地址中,即地址
0x0011
中。
小端
模式则相反。
我们常用的 x86 结构是
小端
模式,所以上面的图数据会“倒着放”,低位字节放在了
低
地址,
高
位字节放在了
高
地址。而 KEIL C51 则为
大端
模式。很多的ARM,DSP都为
小端
模式。有些ARM处理器还可以由硬件来选择为大端模式还是
小端
模式。
判断大小端的程序
思路:设一个变量a,在内存中的存放方式(十六进制数)为:01 00 00 00 ... 00
(小端),地址第一位是1,如果是大端存储:则应该是:00 .... 00 00 00 01,
地址第一位是0,可以把 a 的地址取出第一位。
如果第一位地址 == 1,说明是小端存储,
第一位地址 == 0,说明是大端存储,
取出 int类型a 的 地址 第一位方法:
*(char*)&a
。
代码:
#include <stdio.h>
//小端返回1
//大端返回0
int pan_duan()
{
int a = 1;
return *(char*)&a;
}
int main()
{
int ret = pan_duan();
if(ret == 1)
printf("小端\n");
else
printf("大端\n");
return 0;
}
在VS的运行结果

三、 练习
第一题:判断下面程序的输出内容 (unsigned 和 signed的区别) 。
#include <stdio.h>
int main()
{
char a = -1;
signed char b = -1;
unsigned char c = -1;
printf("a=%d,b=%d,c=%d", a, b, c);
return 0;
}
运行结果:
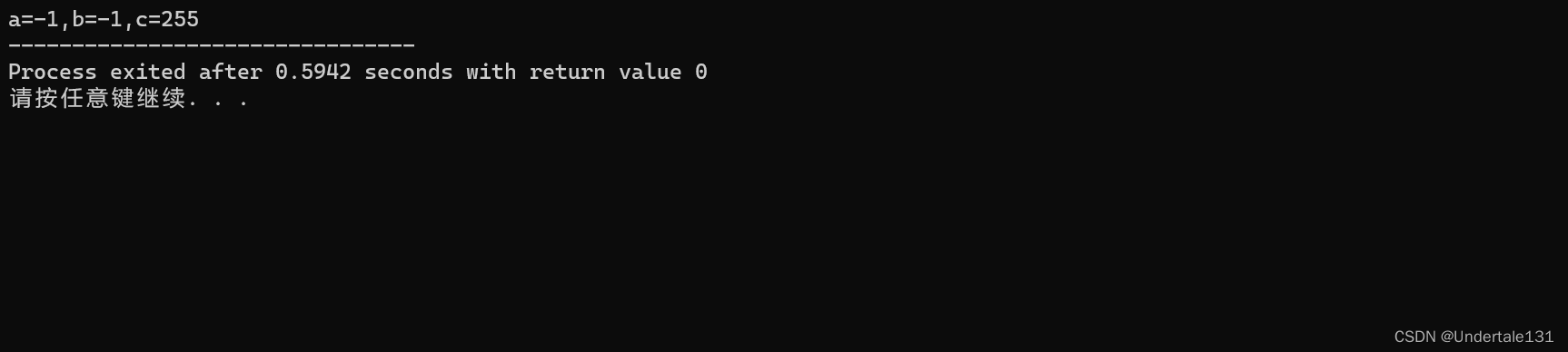
解析
#include <stdio.h>
int main()
{
char a = -1;
//10000000000000000000000000000001 -- 原码
//11111111111111111111111111111110 -- 反码
//11111111111111111111111111111111 -- 补码
// -1是整数,存进char类型中会发生截断
// 11111111 -- 补码,截断获取最低8位
// 最高位 是 符号位
signed char b = -1;
//和 char a 相同
unsigned char c = -1;
// 11111111 -- 补码,截断获取最低8位
// 最高位 是 数值位
printf("a=%d,b=%d,c=%d", a, b, c);
//%d - 十进制形式打印有符号整型数据,
//这里会发生 整型提升
// 11111111 -- 补码,截断获取最低8位
//
// 整型提升,有符号位按符号位补满,补满后:
//11111111111111111111111111111111 -- 整型提升后补码
//11111111111111111111111111111110 -- 反码
//10000000000000000000000000000001 -- 原码
//
//a = -1
//b = -1
// 整型提升,无符号位高位补0,补满后:
//00000000000000000000000011111111 -- 整型提升后补码
// 整数原码、反码、补码相同
//c = 255
return 0;
}
第二题:判断下面程序的输出内容是否相同(使用 %u 打印 有符号整型) 。
#include <stdio.h>
int main()
{
char a = -128;
printf("%u\n", a);
return 0;
}
#include <stdio.h>
int main()
{
char a = 128;
printf("%u\n", a);
return 0;
}
运行结果1

运行结果2

解析
#include <stdio.h>
int main()
{
char a = -128;
//10000000000000000000000010000000 -- 原码
//11111111111111111111111101111111 -- 反码
//11111111111111111111111110000000 -- 补码
// 截断后:
// 10000000 -- 截断后补码
printf("%u\n", a);
// %u -- 十进制形式打印无符号的整型
// 对 char 变量 打印 整型数字,进行整型提升
// char类型 有符号位,按符号位补满:
//11111111111111111111111110000000 -- 补满后的补码
//因为是 无符号整数 打印,所以 原码、反码、补码 相同
// 那么这个数的原码的十进制表示则为4294967168
return 0;
}
#include <stdio.h>
int main()
{
char a = 128;
//00000000000000000000000010000000 -- 原码
//11111111111111111111111101111111 -- 反码
//11111111111111111111111110000000 -- 补码
// 截断后:
// 10000000 -- 截断后补码
// 跟-128是一样的,
printf("%u\n", a);
// %u -- 十进制形式打印无符号的整型
// 对 char 变量 打印 整型数字,进行整型提升
// char类型 有符号位,按符号位补满:
//11111111111111111111111110000000 -- 补满后的补码
//因为是以 无符号整数 打印,所以 原码、反码、补码 相同
// 所以这个数的原码的十进制表示与1.一样为4294967168
return 0;
}
第三题:判断下面程序的输出内容 (用%d打印:有符号整型 + 无符号整型)
#include <stdio.h>
int main()
{
int a = -20;
unsigned int b = 10;
printf("%d\n", a + b);
return 0;
}
运行结果:

解析:
#include <stdio.h>
int main()
{
int a = -20;//有符号整型:
//10000000000000000000000000010100 -- 原码
//11111111111111111111111111101011 -- 反码
//11111111111111111111111111101100 -- 补码
//无符号整型:
unsigned int b = 10;
//00000000000000000000000000001010 -- 原码
// 原码、反码、补码 相同
printf("%d\n", a + b);
// a的补码 和 b的补码 相加
//11111111111111111111111111101100 -- a的补码
//00000000000000000000000000001010 -- b的补码
//11111111111111111111111111110110 -- 两补码相加后的补码
//该补码再通过%d打印有符号数,最高位是符号位,知道补码,要计算得到原码
//11111111111111111111111111110101 -- 反码
// 反码 符号位 不变,其它位 按位取反
//10000000000000000000000000001010 -- 原码 -->
//-10
return 0;
}
第四题:判断下面程序的输出内容 (无符号整数进行自减循环)
#include <stdio.h>
#include <windows.h>
int main()
{
unsigned int i;
for (i = 9; i >= 0; i--)
{
printf("%u\n", i);
Sleep(1000);
//单位是毫秒,休眠1秒再继续下个语句
}
return 0;
}
运行结果:

解析:
#include <stdio.h>
#include <windows.h>
int main()
{
unsigned int i;
for (i = 9; i >= 0; i--)
{
//减到i= -1时-1被当成一个无符号数来看待,
//而-1的二进制序列为32个一值为---->4294967295
//因此 i 恒 >= 0,程序进入死循环
printf("%u\n", i);
Sleep(1000);
}
return 0;
}
}
第五题:判断下面程序的输出内容 (字符数组存储整型数字)
#include <stdio.h>
#include <string.h>
int main()
{
char a[1000];
int i;
for (i = 0; i < 1000; i++)
{
a[i] = -1 - i;
}
printf("%d", strlen(a));
return 0;
}
运行结果

解析:
#include <stdio.h>
#include <string.h>
int main()
{
char a[1000];
//char类型数组,整型数字只能存储0~-128
int i;
for (i = 0; i < 1000; i++)
{
a[i] = -1 - i;//-1,-2......
}
//-1,-2,-3...-128,127,126,...3,2,1,0 -- 一次存256个元素
//-1,-2,-3...-128,127,126,...3,2,1,0
//. . . . . . . . . . . . . . . . . . .
printf("%d", strlen(a));
//strlen 是求字符串长度的,
//统计的是 \0 之前出现的字符的个数
// \0 的ASCII码值是 0,从-1,-2,-3...-128,127,126,...3,2,1,0....
//中找到0就停止计算。
return 0;
}
第六题:判断下面程序是否为死循环 (unsigned char 取值范围)
#include <stdio.h>
unsigned char i = 0;
int main()
{
for (i = 0; i <= 255; i++)
{
printf("hello world\n");
}
return 0;
}
运行结果:

解析:
//unsigned char 取值范围:
#include <stdio.h>
unsigned char i = 0;//全局变量
//unsigned char 的整型取值范围是:0~255
int main()
{
for (i = 0; i <= 255; i++)
{
//i++到i = 255时,因为i是无符号字符型,范围为0~255
// 255 再 +1 又变成 0 ,所以 i 始终 <= 255,死循环打印 hello world
printf("hello world\n");
}
return 0;
}