1. Job概念
在使用FATE启动一个训练模型任务(Job)时,必须的两个参数文件:dsl和conf(Task Submit Runtime Conf );
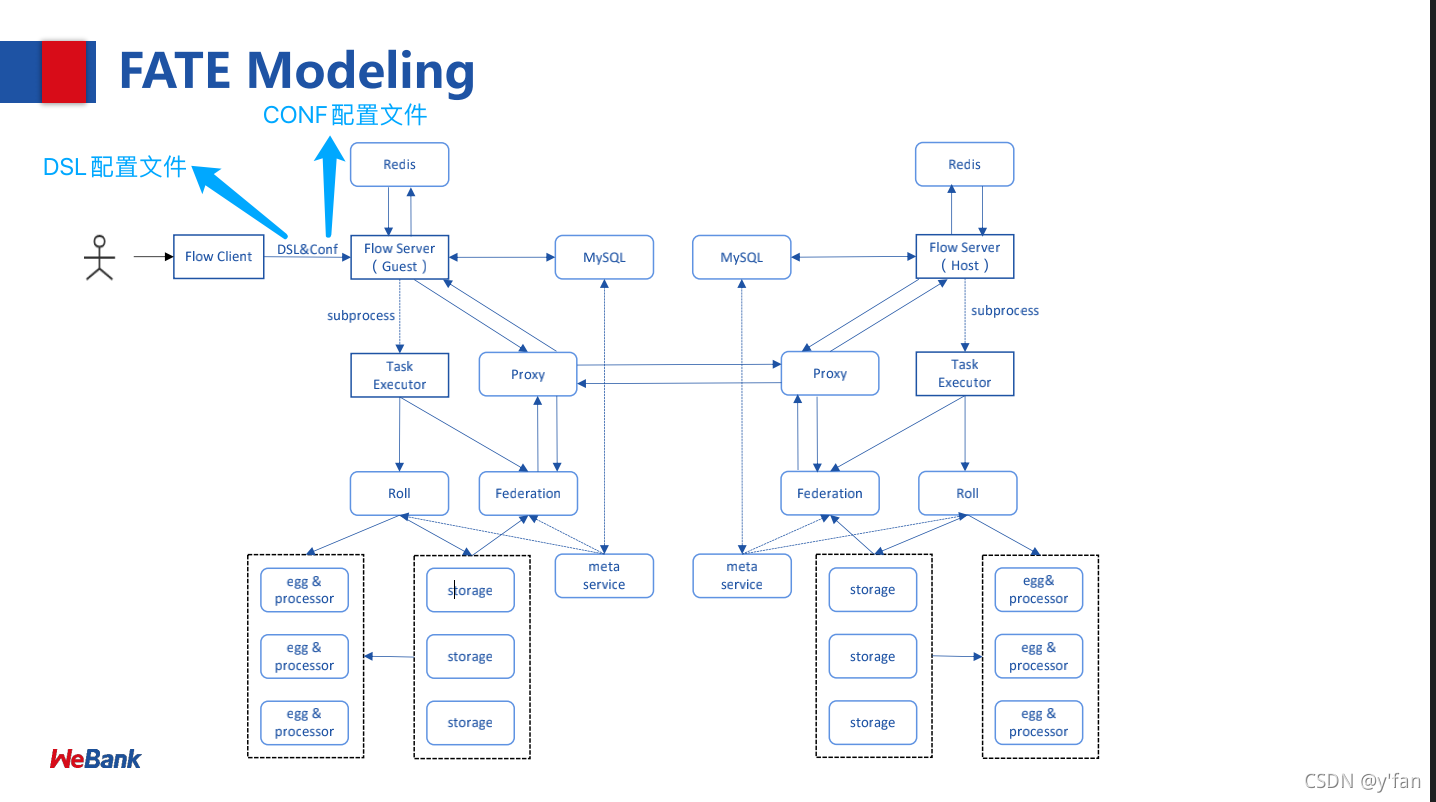
任务启动流程图:
2. 关于DSL语言
任务配置与运行配置(DSL & Task Submit Runtime Conf Setting)V2
为了让任务模型的构建更加灵活,目前 FATE 使用了一套
自定的领域特定语言 (DSL)
来描述任务。在 DSL 中,各种模块(例如数据读写 data_io,特征工程 feature-engineering, 回归 regression,分类 classification)可以通向一个有向无环图 (DAG) 组织起来。通过各种方式,用户可以根据自身的需要,灵活地组合各种算法模块。
除此之外,每个模块都有不同的参数需要配置,不同的 party 对于同一个模块的参数也可能有所区别。为了简化这种情况,对于每一个模块,FATE 会将所有 party 的不同参数保存到同一个运行配置文件(Submit Runtime Conf)中,并且所有的 party 都将共用这个配置文件。这个指南将会告诉你如何创建一个 DSL 配置文件。
V2配置官网参考
3. DSL配置说明
3.1. 概要
DSL 的配置文件采用 json 格式,实际上,整个配置文件就是一个 json 对象 (dict)。通常用来定义模型训练计划,也是对FATE已实现的个组件进行排列,训练计划以此排列顺序执行;
3.2. Components
在这个 dict 的第一级是 “components”,用来表示这个任务将会使用到的各个模块,每个独立的模块定义在 “components” 之下,所有数据需要通过Reader模块从数据存储拿取数据,注意
Reader模块仅有输出output
3.3. module
用来指定使用的模块。
模块名参考FATE ML算法列表
,与/fate/python/federatedml/conf/setting_conf 下各个模块的文件名保持一致(不包括 .json 后缀)。
3.4. input
分为两种输入类型,分别是 Data和 Model。
Data输入,分为三种输入类型:
1. data: 一般被用于 data_io 模块, feature_engineering 模块或者 evaluation 模块;
2. train_data: 一般被用于 homo_lr, hetero_lr 和 secure_boost 模块。如果出现了 train_data
字段,那么这个任务将会被识别为一个 fit 任务;
4. validate_data: 如果存在 train_data 字段,那么该字段是可选的。如果选择保留该字段,则指
向的数据将会作为 validation set
5. test_data: 用作预测数据,如提供,需同时提供model输入。
Model输入,分为两种输入类型:
1. model: 用于同种类型组件的模型输入。
2. isometric_model: 用于指定继承上游组件的模型输入
3.5. output
数据输出,分为四种输出类型:
1. data: 常规模块数据输出;
2. train_data: 仅用于Data Split;
3. validate_data: 仅用于Data Split;
4. test_data: 仅用于Data Split;
模型输出
1. 仅使用model;
3.6. DSL配置示例
训练模式,用户可以使用其他算法模块替代HeteroSecureBoost,注意模块名hetero_secureboost_0也要一起更改;
{
"components": {
"reader_0": {
"module": "Reader",
"output": {
"data": [
"data"
]
}
},
"dataio_0": {
"module": "DataIO",
"input": {
"data": {
"data": [
"reader_0.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
},
"intersection_0": {
"module": "Intersection",
"input": {
"data": {
"data": [
"dataio_0.data"
]
}
},
"output": {
"data": [
"data"
]
}
},
"hetero_secureboost_0": {
"module": "HeteroSecureBoost",
"input": {
"data": {
"train_data": [
"intersection_0.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
},
"evaluation_0": {
"module": "Evaluation",
"input": {
"data": {
"data": [
"hetero_secureboost_0.data"
]
}
},
"output": {
"data": [
"data"
]
}
}
}
}
4. Submit Runtime Conf
dslV2版本该文件为运行配置文件,主要由以下四个主要部分组成:
- dsl version:{}
- initiator:{}
- role:{}
- job parameters:{}
- component_parameters:{}
4.1.
dsl version:
配置版本,默认为1,建议配置为2;
"dsl_version": "2"
4.2.
initiator:
用户需要定义 initiator。
1.发起方,包括:任务发起方的role和party_id,例如:
"initiator": {
"role": "guest",
"party_id": 9999
}
4.3
role:
所有参与方:包含各参与方信息, 在 role 字段中,每一个元素代表一种角色以及承担这个角色的 party_id。每个角色的 party_id 以列表形式存在,因为一个任务可能涉及到多个 party 担任同一种角色。例如:
"role": {
"guest": [9999],
"host": [10000],
"arbiter": [10000]
}
各角色官方解释:
1. Guest表示数据应用方,在纵向算法中,Guest往往是有标签y的一方。一般是由Guest发起建模流程;
2. Host是数据提供方;
3. arbiter是用来辅助多方完成联合建模的,主要的作用是用来聚合梯度或者模型,比如纵向lr里面,各方将自己一半的梯度发送给arbiter,然后arbiter再联合优化等等,arbiter还参与以及分发公私钥,进行加解密服务等等;
注意:
- 在多方参与训练模型时,guest不能参与arbiter;
- 在单个一方发起训练模型时,由于只有一个节点,数据提供方,使用方都是一个机构,guest,host,arbiter皆是统一party_id;
4.4.
job parameters:
配置作业运行时的主要系统参数;参数应用范围策略设置:
1. 应用于所有参与方,使用common范围标识符;
2. 仅应用于某参与方,使用role范围标识符,使用role:party_index定位被指定的参与方,直接指定的参数优先级高于common参数
示例:
"common": {
}
"role": {
"guest": {
"0": {
}
}
}
其中common下的参数应用于所有参与方,role-guest-0配置下的参数应用于guest角色0号下标的参与方 ;
注意,当前版本系统运行参数未对仅应用于某参与方做严格测试,建议优先选用common;
job parameters具体参数详解:
| 配置项 | 默认值 | 支持值 | 说明 |
|---|---|---|---|
| job_type | train | train, predict | 任务类型 |
| work_mode | 0 | 0, 1 | 0代表单方单机版,1代表多方分布式版本 |
| backend | 0 | 0, 1, 2 | 0代表EGGROLL,1代表SPARK加RabbitMQ,2代表SPARK加Pulsar |
| model_id | – | – | 模型id,预测任务需要填入 |
| model_version | – | – | 模型version,预测任务需要填入 |
| task_cores | 4 | 正整数 | 作业申请的总cpu核数 |
| task_parallelism | 1 | 正整数 | task并行度 |
| computing_partitions | task所分配到的cpu核数 | 正整数 | 计算时数据表的分区数 |
| eggroll_run | 无 | processors_per_node等 | eggroll计算引擎相关配置参数,一般无须配置,由task_cores自动计算得到,若配置则task_cores参数不生效 |
| spark_run | 无 | num-executors, executor-cores等 | spark计算引擎相关配置参数,一般无须配置,由task_cores自动计算得到,若配置则task_cores参数不生效 |
| rabbitmq_run | 无 | queue, exchange等 | rabbitmq创建queue、exchange的相关配置参数,一般无须配置,采取系统默认值 |
| pulsar_run | 无 | producer, consumer等 | pulsar创建producer和consumer时候的相关配置,一般无需配置。 |
| federated_status_collect_type | PUSH | PUSH, PULL | 多方运行状态收集模式,PUSH表示每个参与方主动上报到发起方,PULL表示发起方定期向各个参与方拉取 |
| timeout | 259200 (3天) | 正整数 | 任务超时时间,单位秒 |
针对以下常用参数进行详解:
4.4.1.
backend参数:
1. 三大类引擎具有一定的支持依赖关系,例如Spark计算引擎当前仅支持使用HDFS作为中间数据存储引擎;
2. work_mode + backend会自动依据支持依赖关系,产生对应的三大引擎配置computing、storage、federation;
3. 开发者可自行实现适配的引擎,并在runtime config配置引擎;
参考配置,共有四种:
1. 使用eggroll作为backend,采取默认cpu分配计算策略时的配置;
2. 使用eggroll作为backend,采取直接指定cpu等参数时的配置
3. 使用spark加rabbitMQ作为backend,采取直接指定cpu等参数时的配置
4. 使用spark加pulsar作为backend;
示例:
"job_parameters": {
"common": {
"job_type": "train",
"work_mode": 1,
"backend": 1,
"spark_run": {
"num-executors": 1,
"executor-cores": 2
},
"task_parallelism": 2,
"computing_partitions": 8,
"timeout": 36000,
"rabbitmq_run": {
"queue": {
"durable": true
},
"connection": {
"heartbeat": 10000
}
}
}
}
4.4.2. 资源管理详细说明
1.5.0版本开始,为了进一步管理资源,fateflow启用更细粒度的cpu cores管理策略,去除早前版本直接通过限制同时运行作业个数的策略。
包括:总资源配置、运行资源计算、资源调度,
详情参考
4.5. component_parameters:组件运行参数
参数应用范围策略设置:
1. 应用于所有参与方,使用common范围标识符;
2. 仅应用于某参与方,使用role范围标识符,使用role:party_index定位被指定的参与方,
直接指定的参数优先级高于common参数;
- 示例1:
"commom": {
}
"role": {
"guest": {
"0": {}
}
"host":{
"0": {}
}
}
其中common配置下的参数应用于所有参与方,role-guest-0配置下的参数表示应用于guest角色0号下标的参与方 注意,当前版本组件运行参数已支持两种应用范围策略;
- 示例2:
"component_parameters": {
"common": {
"intersection_0": {
"intersect_method": "raw",
"sync_intersect_ids": true,
"only_output_key": false
},
"hetero_lr_0": {
"penalty": "L2",
"optimizer": "rmsprop",
"alpha": 0.01,
"max_iter": 3,
"batch_size": 320,
"learning_rate": 0.15,
"init_param": {
"init_method": "random_uniform"
}
}
},
"role": {
"guest": {
"0": {
"reader_0": {
"table": {"name": "breast_hetero_guest", "namespace": "experiment"}
},
"dataio_0":{
"with_label": true,
"label_name": "y",
"label_type": "int",
"output_format": "dense"
}
}
},
"host": {
"0": {
"reader_0": {
"table": {"name": "breast_hetero_host", "namespace": "experiment"}
},
"dataio_0":{
"with_label": false,
"output_format": "dense"
}
}
}
}
}
示例参数说明:
- 上述示例组件名称是在DSL配置文件中定义的,该配置文件与其对应;
- intersection_0与hetero_lr_0两个组件的运行参数,放在common范围下,应用于所有参与方;
- 对于reader_0与dataio_0两个组件的运行参数,依据不同的参与方进行特定配置,这是因为通常不同参与方的输入参数并不一致,所有通常这两个组件一般按参与方设置;
4.5.1 多个host方配置
包括多Host任务应在role下列举所有host信息、各host不同的配置应在各自对应模块下分别列举;todo=??
===================================================================================
以上就是一个完整的Submit Runtime Conf运行配置文件的组成内容,下面为一个Submit Runtime Conf配置示例:
{
"dsl_version": "2",
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"host": [
10000
],
"guest": [
9999
]
},
"job_parameters": {
"job_type": "train",
"work_mode": 0,
"backend": 0,
"computing_engine": "STANDALONE",
"federation_engine": "STANDALONE",
"storage_engine": "STANDALONE",
"engines_address": {
"computing": {
"nodes": 1,
"cores_per_node": 20
},
"federation": {
"nodes": 1,
"cores_per_node": 20
},
"storage": {
"nodes": 1,
"cores_per_node": 20
}
},
"federated_mode": "SINGLE",
"task_parallelism": 1,
"computing_partitions": 4,
"federated_status_collect_type": "PULL",
"model_id": "guest-9999#host-10000#model",
"model_version": "202108310831349550536",
"eggroll_run": {
"eggroll.session.processors.per.node": 4
},
"spark_run": {},
"rabbitmq_run": {},
"pulsar_run": {},
"adaptation_parameters": {
"task_nodes": 1,
"task_cores_per_node": 4,
"task_memory_per_node": 0,
"request_task_cores": 4,
"if_initiator_baseline": false
}
},
"component_parameters": {
"role": {
"guest": {
"0": {
"reader_0": {
"table": {
"name": "breast_hetero_guest",
"namespace": "experiment"
}
}
}
},
"host": {
"0": {
"reader_0": {
"table": {
"name": "breast_hetero_host",
"namespace": "experiment"
}
},
"dataio_0": {
"with_label": false
}
}
}
},
"common": {
"dataio_0": {
"with_label": true
},
"hetero_secureboost_0": {
"task_type": "classification",
"objective_param": {
"objective": "cross_entropy"
},
"num_trees": 5,
"bin_num": 16,
"encrypt_param": {
"method": "iterativeAffine"
},
"tree_param": {
"max_depth": 3
}
},
"evaluation_0": {
"eval_type": "binary"
}
}
}
}
5. FATE-FLOW运行job流程原理
- 提交作业后,fate-flow获取job dsl配置文件与job config配置文件(Submit Runtime Conf),存于数据库t_job表对应字段以及/fate/jobs/$jobid/目录;
- 解析job dsl与job config,依据合并参数生成细粒度参数(如上述所说的backend&work_mode对应会生成三个引擎参数), 以及处理参数默认值;
- 将共同配置分发到各参与方并存储,依据参与方的实际信息,生成job_runtime_on_party_conf;
- 每个参与方接收到任务时,均依据job_runtime_on_party_conf执行;
$job id目录包括文件:
1. job_dsl.json
2. job_runtime_conf.json
3. local pipeline_dsl.json
4. train_runtime_conf.json