五一快到到准备去吃个火锅,可是不知道去哪吃,所以就去大众点评网看了看,但是数据太多眼花缭乱,无法找到想去的店铺,所以打算将所有店铺的数据抓取下来然后进行分析一下,说干就干。
老规矩先进行页面分析
页面请求分析

访问具体的某类餐饮是需要登录才能访问到的,经过测试确实如此,如果自接403,请求错误。
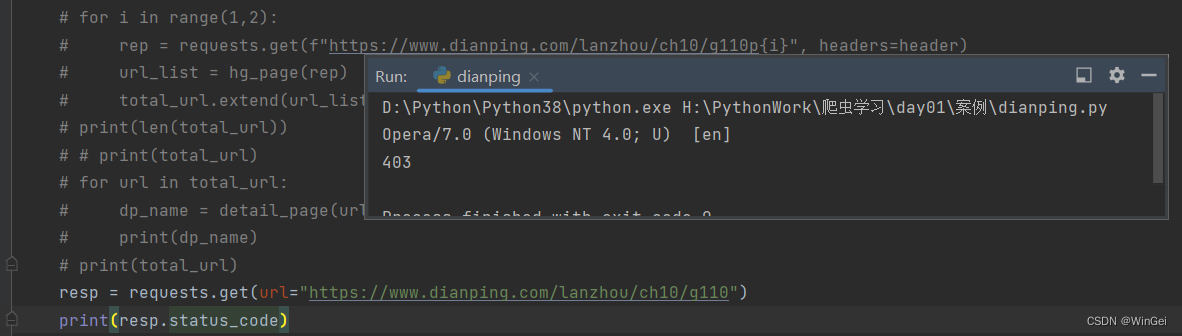
遇到这种需要登录的情况,要嘛使用selenuim自动化爬取,要嘛就是伪造登录什么的,还有一种就是闯一下一下运气,看看携带cookie访问能不能行
登录后我发现这里面的每个请求到携带了这个cookie,所以我就赋值这个cookie看看能不能请求成功
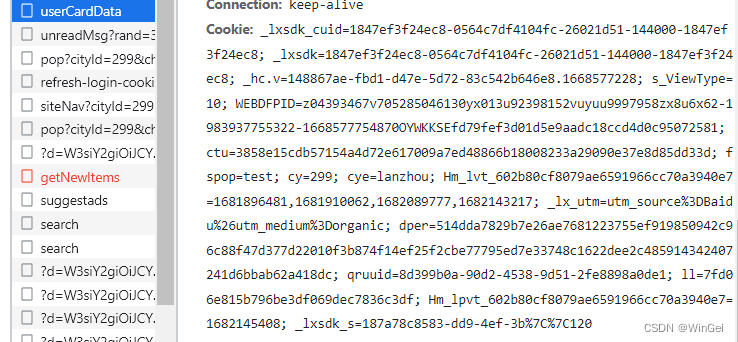
结果证明携带cookie访问是能够成功的,那么接下来就得查看一下放辉来的页面是否和我们所看见的数据是一样的
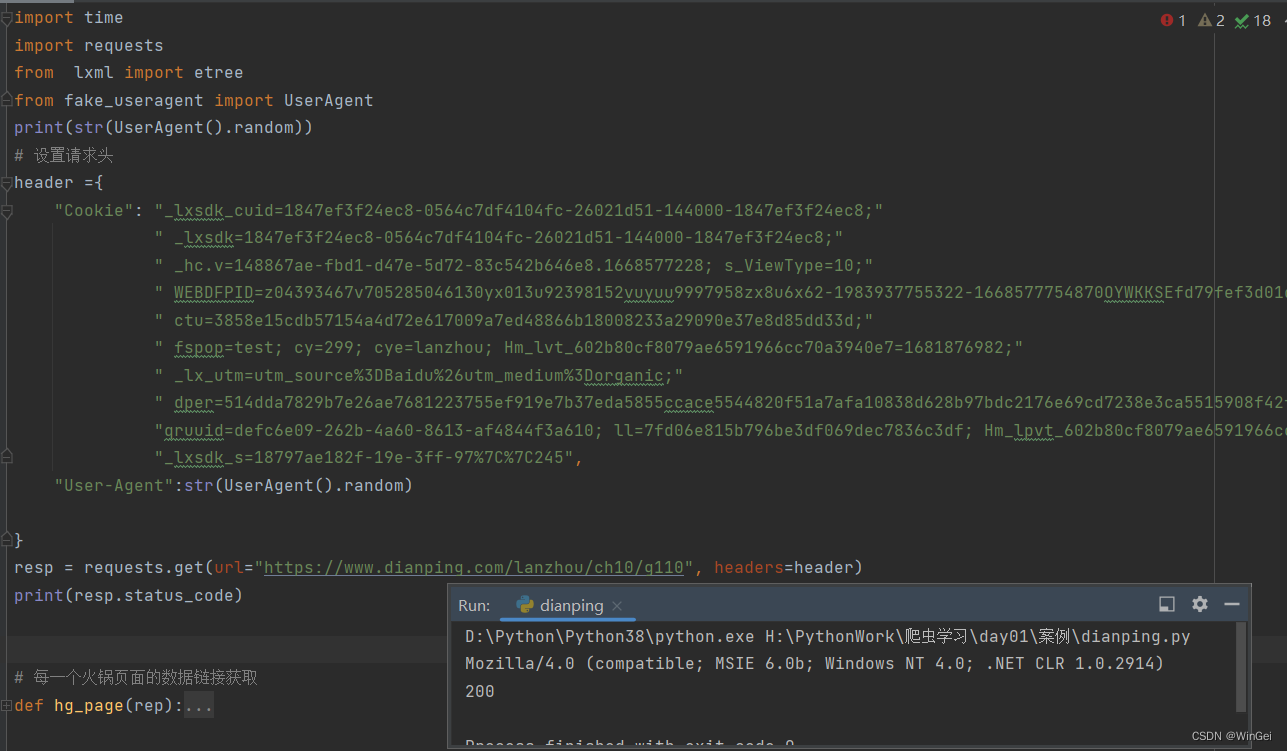
通过页面查找发现,数据在页面中,但是有时候请求也请求不到,可能是浏览器头的问题,我使用了一个随机获取请求头的第三方库,所以可以多试几次,(在以前的时候大众点评在页面上的数据是乱码,那种需要css样式渲染出来的字)
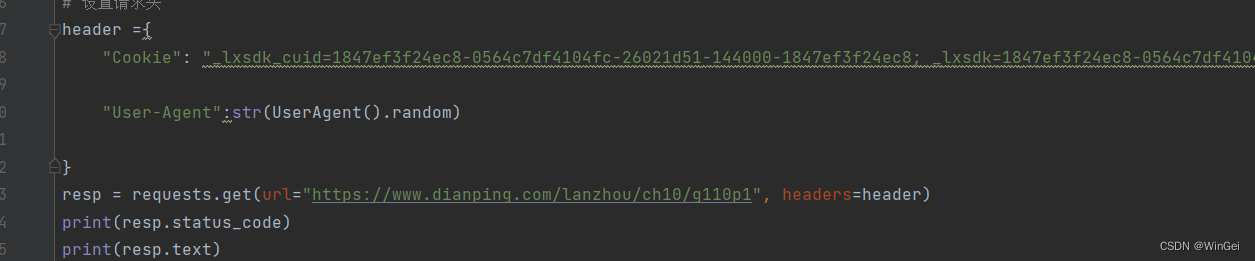

使用xpath页面解析
由于我们需要的是评论数据,所以进入店铺的评论页面,发现评论页面的url路径是
店铺地址+review_all,所以我决定先从首页面获取到所有的店铺地址,然后再挨个请求评论页面的url抓取数据

得到首页的每个店铺url地址
# 每一个火锅页面的数据链接获取
def hg_page(rep):
time.sleep(2)
dp_url_list = []
et= etree.HTML(rep.text)
li_list = et.xpath("//div[@id='shop-all-list']/ul/li")
# print(len(li_list))
# 拿取店铺信息
for li in li_list:
# dp_name = li.xpath("./div[@class='txt']/div[@class='tit']/a/h4/text()")
dp_url = li.xpath("./div[@class='txt']/div[@class='tit']/a/@href")
# print(dp_name)
# print(dp_url[0])
dp_url_list.append(dp_url[0])
# detail_page(dp_url[0])
# 请求评论详情首页
return dp_url_list再对url请求解析
# 具体火锅店铺数据获取
def detail_page(detail_url,headers):
print(f"{detail_url}/review_all")
time.sleep(5)
dic = {}
# 向更多评论页面发送请求
rep_datail = requests.get(f"{detail_url}/review_all", headers=headers)
# print(rep_datail.text)
# 解析详情页面
et_detail = etree.HTML(rep_datail.text)
# 获取店铺名
dp_name = ''.join(et_detail.xpath("//div[@class='review-shop-wrap']//h1[@class='shop-name']/text()"))
# 获取店铺地址
dp_address = ''.join(et_detail.xpath("//div[@class='review-shop-wrap']/div[@class='address-info']/text()")).strip()
# print(dp_address)
# 获取评论列表
comment_list = []
datail_li_list = et_detail.xpath("//div[@class='reviews-items']/ul/li")
# 提取评论数据
for datail_li in datail_li_list:
dic_comment = {}
# 用户名
user_name = ''.join(datail_li.xpath("./div[@class='main-review']/div[@class='dper-info']//text()")).strip()
# 用户评分
user_score = ''.join(datail_li.xpath(
"./div[@class='main-review']/div[@class='review-rank']/span[@class='score']//text()")).split()
# 用户评论
user_comment = ''.join(
datail_li.xpath("./div[@class='main-review']/div[@class='review-words Hide']/text()")).strip()
# 用户评论时间
user_comment_time = ''.join(datail_li.xpath("./div[@class='main-review']//span[@class='time']/text()")).strip()
dic_comment["user_name"] = user_name
dic_comment["user_comment"] = user_comment
comment_list.append(dic_comment)
dic["dp_name"] = dp_name
dic["dp_address"] = dp_address
dic["comment_list"] = comment_list
return dic观察url数据的变化,使用for循环构造多条url进行请求
if __name__ =="__main__":
# # 设置代理池
# proxy = {
# "http": "114.233.70.231:9000",
# "https": "114.233.70.231:9000",
#
# }
# # 拿取20个页面兰州火锅的店铺url
total_url = []
for i in range(1,2):
rep = requests.get(f"https://www.dianping.com/lanzhou/ch10/g110p{i}", headers=header)
url_list = hg_page(rep)
total_url.extend(url_list)
print(len(total_url))
# print(total_url)
# 请求每个详情页
for url in total_url:
dp_name = detail_page(url,header)
print(dp_name)
print(total_url)
完整代码
import time
import requests
from lxml import etree
from fake_useragent import UserAgent
print(str(UserAgent().random))
# 设置请求头
header ={
"Cookie": "_lxsdk_cuid=1847ef3f24ec8-0564c7df4104fc-26021d51-144000-1847ef3f24ec8; _lxsdk=1847ef3f24ec8-0564c7df4104fc-26021d51-144000-1847ef3f24ec8; _hc.v=148867ae-fbd1-d47e-5d72-83c542b646e8.1668577228; s_ViewType=10; WEBDFPID=z04393467v705285046130yx013u92398152vuyuu9997958zx8u6x62-1983937755322-1668577754870OYWKKSEfd79fef3d01d5e9aadc18ccd4d0c95072581; ctu=3858e15cdb57154a4d72e617009a7ed48866b18008233a29090e37e8d85dd33d; fspop=test; cy=299; cye=lanzhou; Hm_lvt_602b80cf8079ae6591966cc70a3940e7=1681896481,1681910062,1682089777,1682143217; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; dper=514dda7829b7e26ae7681223755ef919850942c96c88f47d377d22010f3b874f14ef25f2cbe77795ed7e33748c1622dee2c485914342407241d6bbab62a418dc; qruuid=8d399b0a-90d2-4538-9d51-2fe8898a0de1; ll=7fd06e815b796be3df069dec7836c3df; Hm_lpvt_602b80cf8079ae6591966cc70a3940e7=1682145408; _lxsdk_s=187a78c8583-dd9-4ef-3b%7C%7C120",
"User-Agent":str(UserAgent().random)
}
# 每一个火锅页面的数据链接获取
def hg_page(rep):
time.sleep(2)
dp_url_list = []
et= etree.HTML(rep.text)
li_list = et.xpath("//div[@id='shop-all-list']/ul/li")
# print(len(li_list))
# 拿取店铺信息
for li in li_list:
# dp_name = li.xpath("./div[@class='txt']/div[@class='tit']/a/h4/text()")
dp_url = li.xpath("./div[@class='txt']/div[@class='tit']/a/@href")
# print(dp_name)
# print(dp_url[0])
dp_url_list.append(dp_url[0])
# detail_page(dp_url[0])
# 请求评论详情首页
return dp_url_list
# 具体火锅店铺数据获取
def detail_page(detail_url,headers):
print(f"{detail_url}/review_all")
time.sleep(5)
dic = {}
# 向更多评论页面发送请求
rep_datail = requests.get(f"{detail_url}/review_all", headers=headers)
# print(rep_datail.text)
# 解析详情页面
et_detail = etree.HTML(rep_datail.text)
# 获取店铺名
dp_name = ''.join(et_detail.xpath("//div[@class='review-shop-wrap']//h1[@class='shop-name']/text()"))
# 获取店铺地址
dp_address = ''.join(et_detail.xpath("//div[@class='review-shop-wrap']/div[@class='address-info']/text()")).strip()
# print(dp_address)
# 获取评论列表
comment_list = []
datail_li_list = et_detail.xpath("//div[@class='reviews-items']/ul/li")
# 提取评论数据
for datail_li in datail_li_list:
dic_comment = {}
# 用户名
user_name = ''.join(datail_li.xpath("./div[@class='main-review']/div[@class='dper-info']//text()")).strip()
# 用户评分
user_score = ''.join(datail_li.xpath(
"./div[@class='main-review']/div[@class='review-rank']/span[@class='score']//text()")).split()
# 用户评论
user_comment = ''.join(
datail_li.xpath("./div[@class='main-review']/div[@class='review-words Hide']/text()")).strip()
# 用户评论时间
user_comment_time = ''.join(datail_li.xpath("./div[@class='main-review']//span[@class='time']/text()")).strip()
dic_comment["user_name"] = user_name
dic_comment["user_comment"] = user_comment
comment_list.append(dic_comment)
dic["dp_name"] = dp_name
dic["dp_address"] = dp_address
dic["comment_list"] = comment_list
return dic
if __name__ =="__main__":
# # 设置代理池
# proxy = {
# "http": "114.233.70.231:9000",
# "https": "114.233.70.231:9000",
#
# }
# # 拿取20个页面兰州火锅的店铺url
total_url = []
for i in range(1,2):
rep = requests.get(f"https://www.dianping.com/lanzhou/ch10/g110p{i}", headers=header)
url_list = hg_page(rep)
total_url.extend(url_list)
print(len(total_url))
# print(total_url)
# 请求每个详情页
for url in total_url:
dp_name = detail_page(url,header)
print(dp_name)
print(total_url)
抓取成功
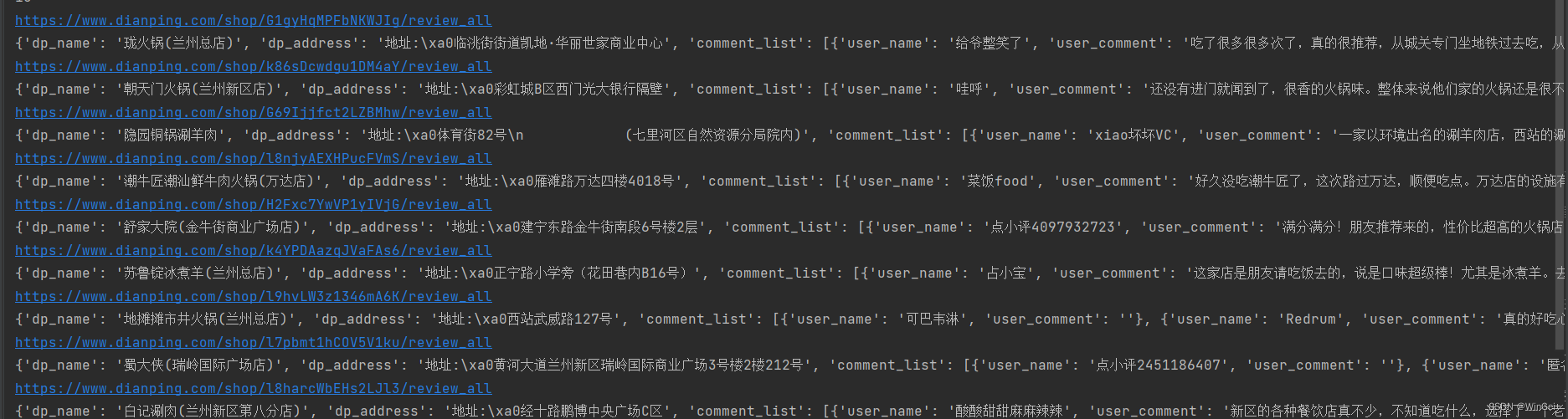
总结
在爬取过程最好使用停顿一下,不然网站有反爬机制,会限制你的ip访问,你用浏览器都请求不了,页面是403错误,所以我注释了使用代理的代码,这个代理是免费的,使用起来有点错误,显示请求连接失败,如果手头宽松的话可以花钱购买ip代理进行访问,这样就不用担心ip被限制。
