1.3.1 InsertIntoHiveTable类源码解析
1.3.1.1 背景
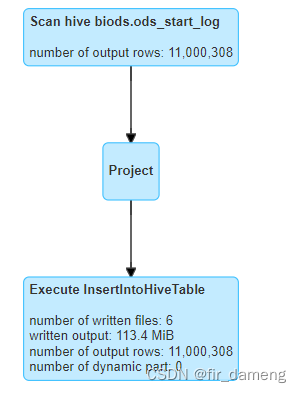
读取数据,经过处理后,最终写入 hive表,这里研究下写入原理。抛出如下几个问题?
1、task处理完数据后,如何将数据放到表的location目录下?
2、这类写入表的task,是如何从spark sql 逻辑计划/物理计划 转化成 task启动的?
1.3.1.2 spark sql 逻辑计划/物理计划 如何转化成 task(回答问题2)
driver端 调试日志如下(
定位InsertIntoHiveTable物理执行算子的run方法
):
run:84, InsertIntoHiveTable (org.apache.spark.sql.hive.execution)
sideEffectResult$lzycompute:108, DataWritingCommandExec (org.apache.spark.sql.execution.command)
sideEffectResult:106, DataWritingCommandExec (org.apache.spark.sql.execution.command)
executeCollect:120, DataWritingCommandExec (org.apache.spark.sql.execution.command) -- 物理执行计划触发执行
$anonfun$logicalPlan$1:229, Dataset (org.apache.spark.sql) -----org.apache.spark.sql.Dataset#logicalPlan
apply:-1, 76482793 (org.apache.spark.sql.Dataset$$Lambda$1656)
$anonfun$withAction$1:3618, Dataset (org.apache.spark.sql)
apply:-1, 277117675 (org.apache.spark.sql.Dataset$$Lambda$1657)
$anonfun$withNewExecutionId$5:100, SQLExecution$ (org.apache.spark.sql.execution)
apply:-1, 1668179857 (org.apache.spark.sql.execution.SQLExecution$$$Lambda$1665)
withSQLConfPropagated:160, SQLExecution$ (org.apache.spark.sql.execution)
$anonfun$withNewExecutionId$1:87, SQLExecution$ (org.apache.spark.sql.execution)
apply:-1, 216687255 (org.apache.spark.sql.execution.SQLExecution$$$Lambda$1658)
withActive:764, SparkSession (org.apache.spark.sql)
withNewExecutionId:64, SQLExecution$ (org.apache.spark.sql.execution)
withAction:3616, Dataset (org.apache.spark.sql)
<init>:229, Dataset (org.apache.spark.sql)
$anonfun$ofRows$2:100, Dataset$ (org.apache.spark.sql) --- org.apache.spark.sql.Dataset#ofRows
apply:-1, 2116006444 (org.apache.spark.sql.Dataset$$$Lambda$925)
withActive:764, SparkSession (org.apache.spark.sql)
ofRows:97, Dataset$ (org.apache.spark.sql)
$anonfun$sql$1:607, SparkSession (org.apache.spark.sql)
apply:-1, 1700143613 (org.apache.spark.sql.SparkSession$$Lambda$787)
withActive:764, SparkSession (org.apache.spark.sql)
sql:602, SparkSession (org.apache.spark.sql) -- org.apache.spark.sql.SparkSession#sql 用户编写spark sql语句
main:50, SparkSqlHive$ (org.example.sparksql)
main:-1, SparkSqlHive (org.example.sparksql)
org.apache.spark.sql.Dataset#ofRows
def ofRows(sparkSession: SparkSession, logicalPlan: LogicalPlan, tracker: QueryPlanningTracker)
: DataFrame = sparkSession.withActive {
// logicalPlan 解析了的逻辑计划,qe 已经生成了物理执行计划
val qe = new QueryExecution(sparkSession, logicalPlan, tracker)
qe.assertAnalyzed()
new Dataset[Row](qe, RowEncoder(qe.analyzed.schema))
}
org.apache.spark.sql.Dataset#logicalPlan
@transient private[sql] val logicalPlan: LogicalPlan = {
// For various commands (like DDL) and queries with side effects, we force query execution
// to happen right away to let these side effects take place eagerly.
val plan = queryExecution.analyzed match {
case c: Command =>
// queryExecution 已经生成完了的物理执行计划
LocalRelation(c.output, withAction("command", queryExecution)(_.executeCollect()))
case u @ Union(children) if children.forall(_.isInstanceOf[Command]) =>
LocalRelation(u.output, withAction("command", queryExecution)(_.executeCollect()))
case _ =>
queryExecution.analyzed
}
if (sparkSession.sessionState.conf.getConf(SQLConf.FAIL_AMBIGUOUS_SELF_JOIN_ENABLED)) {
plan.setTagValue(Dataset.DATASET_ID_TAG, id)
}
plan
}
总结如下:
一段sql语句–》物理执行计划-》最底层算子提交 job(物理计划被执行) ->内部提交task-》被调度执行,
其中物理执行计划示例如下:
InsertIntoHiveTable 就是最底层的算子,该算子实现中会提交job
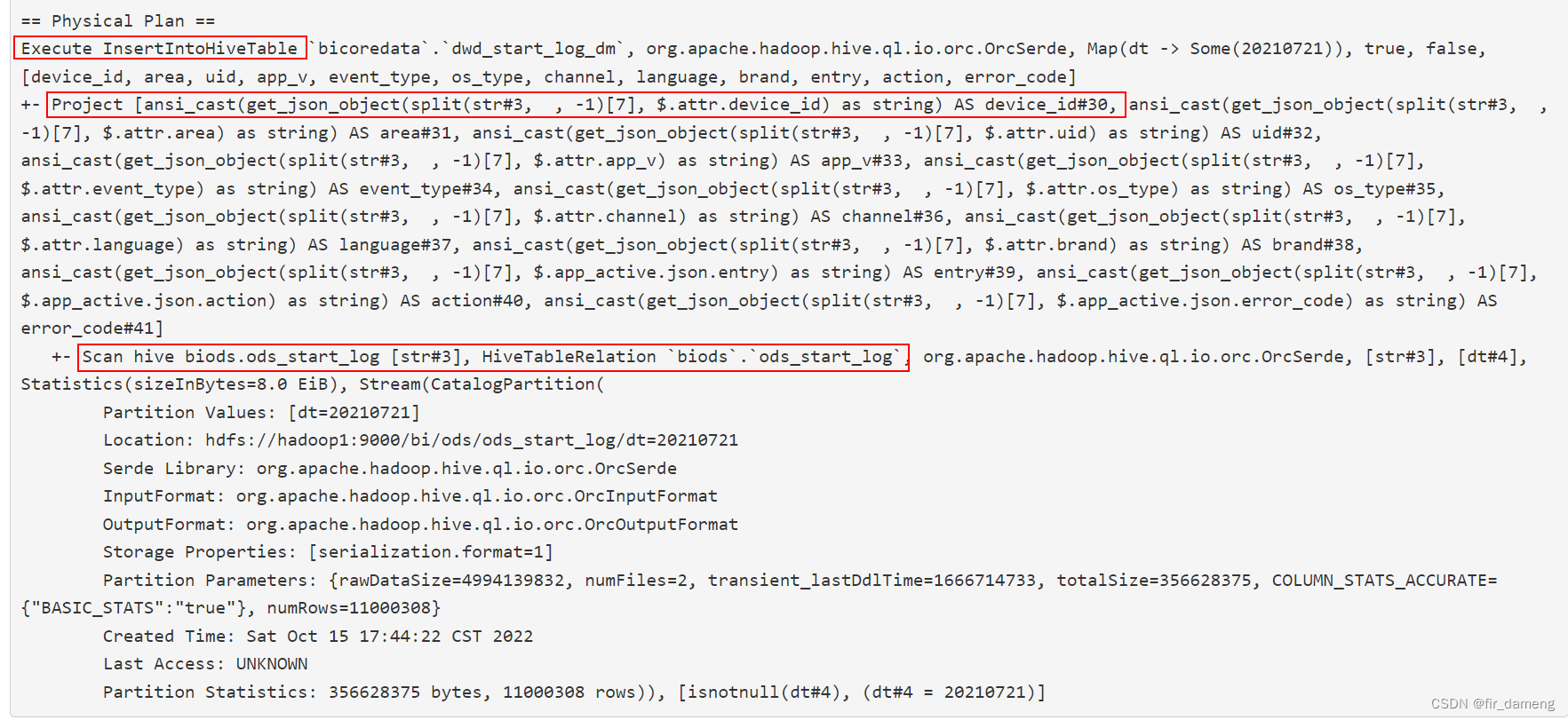
物理计划被执行触发点如下:
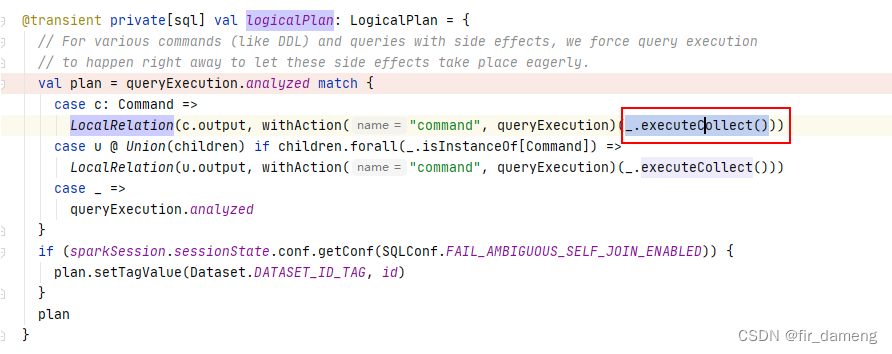
整体流程示意图如下:
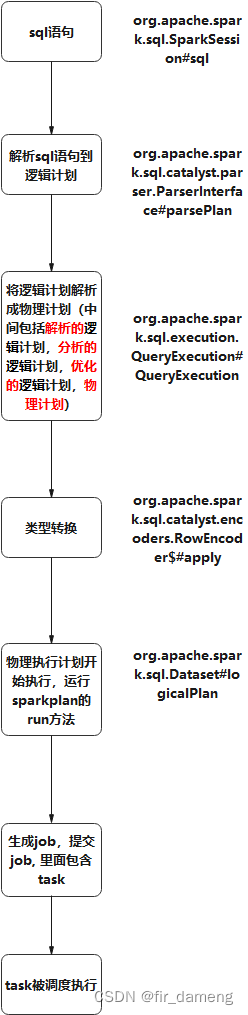
物理执行计划中,InsertIntoHiveTable算子的run方法执行示意图如下:
注意
该流程是在driver端执行
,直到提交job

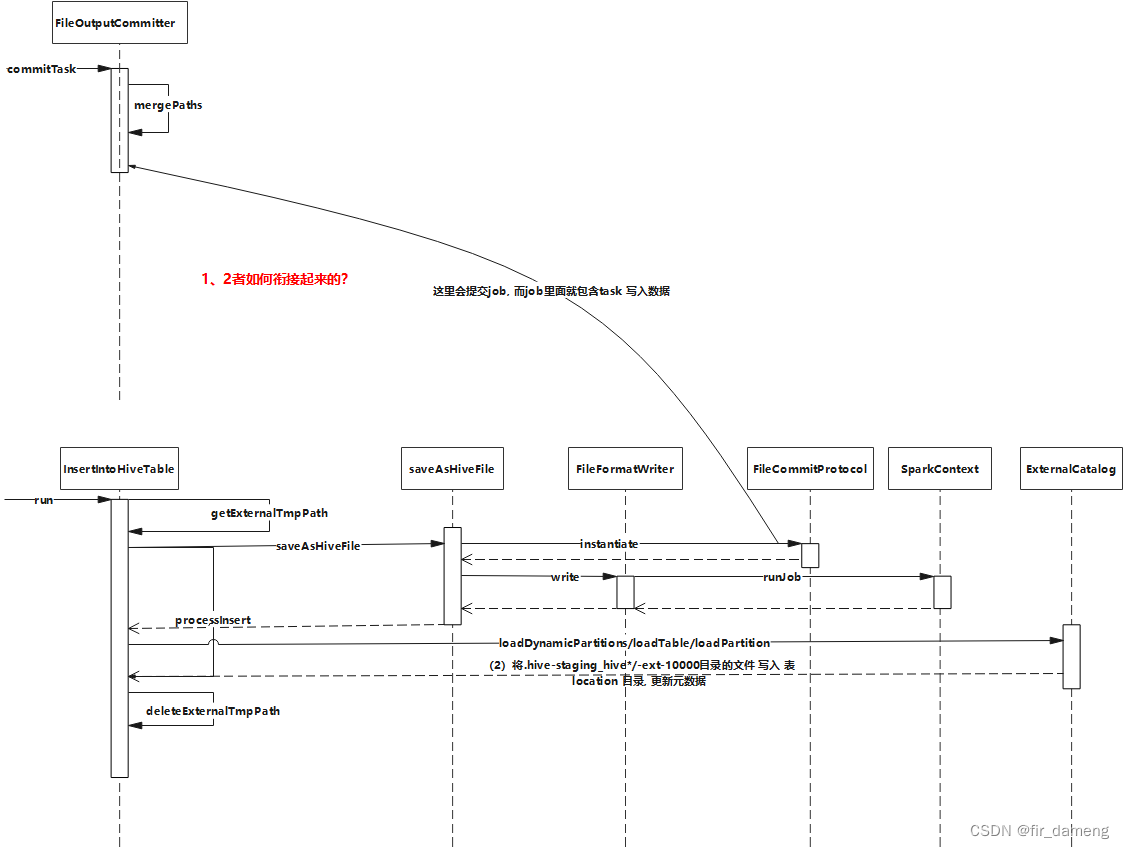
结合具体日志流程如下:
(1) 创建相关临时目录,提交task调度执行

(2)task执行,写入数据到.hive-staging_hive_*/-ext-10000目录(
回答问题1
)

(3)将.hive-staging_hive*/-ext-10000目录的文件 写入 表location 目录, 更新元数据(
回答问题1
)

1.3.1.3 task如何commit数据(详细回答问题1)
参考:https://www.jianshu.com/p/01ab5f0f22df
总结如下:
-
对于spark的InsertIntoHiveTable,结果rdd的每个partition的数据都有相应的task负责数据写入,而每个task都会在目标hive表的location目录下的.hive-staging_hive*/-ext-10000目录中创建相应的临时的staging目录,当前task的所有数据都会先写入到这个staging目录中;
-
当单个task写入完成后,会调用FileOutputCommitter.commitTask把task的staging目录下的数据文件都move到.hive-staging_hive*/-ext-10000下面,
这个过程就是单个task的commit
-
当一个spark job的所有task都执行完成并commit成功后,spark会调用FileOutputCommitter.commitJob把
临时的staging目录都删除掉,并创建_SUCCESS标记文件
-
当spark成功将数据都写入到staging_hive*/-ext-10000中 (
也就是commitJob成功后
),spark会调用
hive的相应API把数据文件都move到目标hive表的location目录
下,并
更新hive meta data
以enable新的hive partition