(一)hivesql 行转列(collect_set)与列转行(explode和posexplode)
https://blog.csdn.net/zhouqi1991i/article/details/91957007
hivesql 行转列与列转行
列转行函数——collect_set和collect_list
hive里通常通过collect_set和collect_list来进行列转行,其中collect_list为不去重转换,collect_set为去重转换。
下面我们将通过一个实例来进行说明:
创建一个学生成绩表
CREATE table student_score(
stu_id string comment ‘学号’,
stu_name string comment ‘姓名’,
course string comment ‘科目’,
score string comment ‘分数’
) comment ‘学生成绩表’;
学生表数据为:
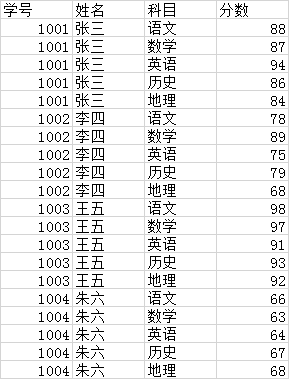
保存后把数据导入创建的表格中:
LOAD DATA INPATH :dataPath OVERWRITE INTO TABLE student_score;
现在我们想要把每个学生的课程和成绩放到一行展示,即每个学生只让他显示一行数据,这时可以使用到列转行函数,使用如下语句:
–使用collect_set函数进行列转行查询
SELECT
stu_id,
stu_name,
concat_ws(’,’,collect_set(course)) as course,
concat_ws(’,’,collect_set(score)) as score
from student_score
group by stu_id,stu_name
查询出的结果为:
序号 stu_id stu_name course score
1 1001 张三 语文,数学,英语,历史,地理 88,87,94,86,84
2 1002 李四 语文,数学,英语,历史,地理 78,89,75,79,68
3 1003 王五 语文,数学,英语,历史,地理 98,97,91,93,92
4 1004 朱六 语文,数学,英语,历史,地理 66,63,64,67,68
建立一个新的学生表,使用上面列转行的结果来作为行转列的例表:
CREATE table student_score_new
as
SELECT
stu_id,
stu_name,
concat_ws(’,’,collect_set(course)) as course,
concat_ws(’,’,collect_set(score)) as score
from student_score
group by stu_id,stu_name;
行转列函数——explode和posexplode
explode函数可以把array或map格式的字段转换成行的形式,当然string形式的字段其实也可以转换,只需要用split函数把字段分割成一个数组的形式即可,比如我们可以把表格中的每个玩家的科目以列的形式查询出来:
–使用explode函数进行列转行查询
SELECT stu_id,
stu_name,
ecourse
from student_score_new
lateral view explode(split(course,’,’)) cr as ecourse
查询结果如下:
序号 stu_id stu_name ecourse
1 1001 张三 语文
2 1001 张三 数学
3 1001 张三 英语
4 1001 张三 历史
5 1001 张三 地理
6 1002 李四 语文
7 1002 李四 数学
8 1002 李四 英语
9 1002 李四 历史
10 1002 李四 地理
11 1003 王五 语文
12 1003 王五 数学
13 1003 王五 英语
14 1003 王五 历史
15 1003 王五 地理
16 1004 朱六 语文
17 1004 朱六 数学
18 1004 朱六 英语
19 1004 朱六 历史
20 1004 朱六 地理
但是当我们想要查询每个学生课程对应的分数时,使用explode函数会出现如下结果:
例如使用如下语句:
SELECT stu_id,
stu_name,
ecourse,
escore
from student_score_new
lateral view explode(split(course,’,’)) cr as ecourse
lateral view explode(split(score,’,’)) sc as escore;
查询的结果如下:
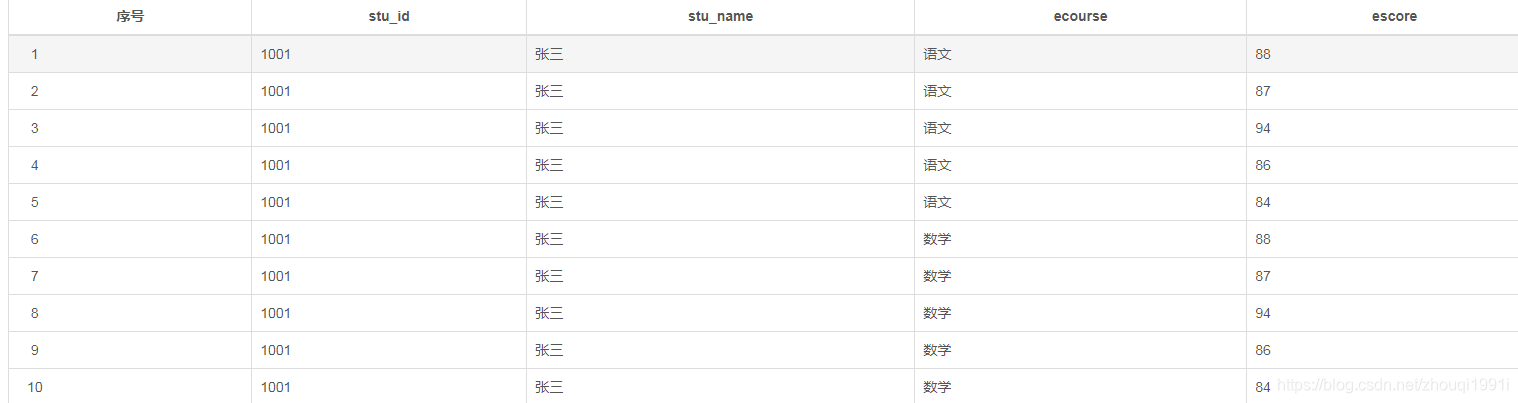
出现这种情况是因为两个并列的explode的sql没办法识别每个科目对应的成绩是多少,对于多个数组的行转列可以使用posexplode函数,例如使用如下查询语句:
–使用posexplode函数进行列转行查询
SELECT stu_id,
stu_name,
ecourse,
escore
from student_score_new
lateral view posexplode(split(course,’,’)) cr as a,ecourse
lateral view posexplode(split(score,’,’)) sc as b,escore
where a=b;
查询结果如下:
序号 stu_id stu_name ecourse escore
1 1001 张三 语文 88
2 1001 张三 数学 87
3 1001 张三 英语 94
4 1001 张三 历史 86
5 1001 张三 地理 84
6 1002 李四 语文 78
7 1002 李四 数学 89
8 1002 李四 英语 75
9 1002 李四 历史 79
10 1002 李四 地理 68
11 1003 王五 语文 98
12 1003 王五 数学 97
13 1003 王五 英语 91
14 1003 王五 历史 93
15 1003 王五 地理 92
16 1004 朱六 语文 66
17 1004 朱六 数学 63
18 1004 朱六 英语 64
19 1004 朱六 历史 67
20 1004 朱六 地理 68
————————————————
版权声明:本文为CSDN博主「、技术萌新」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zhouqi1991i/article/details/91957007
(二)
Hive Explode/Lateral查看多个数组
https://qa.1r1g.com/sf/ask/1446723141/
我有一个具有以下架构的配置单元表:
COOKIE | PRODUCT_ID | CAT_ID | QTY
1234123 [1,2,3] [r,t,null] [2,1,null]
我如何规范化数组,以便得到以下结果
COOKIE | PRODUCT_ID | CAT_ID | QTY
1234123 [1] [r] [2]
1234123 [2] [t] [1]
1234123 [3] null null
我尝试过以下方法:
select concat_ws('|',visid_high,visid_low) as cookie
,pid
,catid
,qty
from table
lateral view explode(productid) ptable as pid
lateral view explode(catalogId) ptable2 as catid
lateral view explode(qty) ptable3 as qty
然而结果是笛卡尔积.
Jerome Banks.. 15
您可以使用Brickhouse中的
numeric_range
和
array_index
UDF(
http://github.com/klout/brickhouse
)来解决此问题.有一篇内容丰富的博客文章详细介绍了
http://brickhouseconfessions.wordpress.com/2013/03/07/exploding-multiple-arrays-at-the-same-time-with-numeric_range/
使用这些UDF,查询将是这样的
select cookie,
array_index( product_id_arr, n ) as product_id,
array_index( catalog_id_arr, n ) as catalog_id,
array_index( qty_id_arr, n ) as qty
from table
lateral view numeric_range( size( product_id_arr )) n1 as n;
小智.. 15
我没有使用任何UDF就找到了解决这个问题的非常好的解决方案,
posexplode
是一个非常好的解决方案:
SELECT COOKIE , ePRODUCT_ID, eCAT_ID, eQTY FROM TABLE LATERAL VIEW posexplode(PRODUCT_ID) ePRODUCT_IDAS seqp, ePRODUCT_ID LATERAL VIEW posexplode(CAT_ID) eCAT_ID AS seqc, eCAT_ID LATERAL VIEW posexplode(QTY) eQTY AS seqq, eDateReported WHERE seqp = seqc AND seqc = seqq;
-
嘿,这行得通!需要注意的是,您的数组需要具有相同的长度,如果没有,则将它们截断为最短的长度。我也不确定它的性能,尤其是在越来越多的侧面视图中。
(3认同
(三)Hive字符串转为复杂格式数据
1、字符串转为map
str_to_map(text[, delimiter1, delimiter2])
使用两个分隔符将文本拆分为键值对。 Delimiter1将文本分成K-V对,Delimiter2分割每个K-V对。对于delimiter1默认分隔符是’,’,对于delimiter2默认分隔符是’=’。
示例:
select str_to_map(‘aaa:11&bbb:22’, ‘&’, ‘:’);
select str_to_map(‘aaa:11&bbb:22’, ‘&’, ‘:’)[‘aaa’];
select str_to_map(‘device_ds:2&uid_cnt:1′,’&’,’,’) –键值分割不到,值会出现Null
综合使用示范:
select a1.appkey,a1.appsource,index_key,index_value
from tab_sum a1
lateral view explode(str_to_map(concat(‘device_ds:’,a1.device_ds_cnt,’&’,’uid_cnt:’,a1.uid_cnt),’&’,’:’)) mid_list_tab as index_key,index_value;
2、字符串转为array
分割字符串函数: split
语法: split(string str, stringpat)
返回值: array
说明: 按照pat字符串分割str,会返回分割后的字符串数组
举例:
select split(‘aaa:11:bbb:22′,’:’);
[“aaa”,”11″,”bbb”,”22″]
select split(‘aaa:11:bbb:22′,’:’)[0];
aaa
3、字符字段去重汇总转成array
collect_set函数:该函数的作用是将某字段的值进行去重汇总,产生Array类型字段。
drop table if exists xxxxx_tabletest;
CREATE TABLE xxxxx_tabletest(
id string,
name string)
ROW FORMAT SERDE
‘org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe’
WITH SERDEPROPERTIES (
‘field.delim’=’,’,
‘line.delim’=’\n’,
‘serialization.format’=’,’);
insert into xxxxx_tabletest(id,name)
values
(‘1′,’A’),
(‘1′,’C’),
(‘1′,’B’),
(‘2′,’B’),
(‘2′,’C’),
(‘2′,’D’),
(‘3′,’B’),
(‘3′,’C’),
(‘3′,’D’);
select id,collect_set(name) from xxxxx_tabletest group by id;
OK
1 [“A”,”C”,”B”]
2 [“B”,”C”,”D”]
3 [“B”,”C”,”D”]
Time taken: 36.966 seconds, Fetched: 3 row(s)
————————————————
版权声明:本文为CSDN博主「BabyFish13」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/BabyFish13/article/details/78951928
(四)
hivesql中的concat函数,concat_ws函数,concat_group函数之间的区别
https://www.cnblogs.com/wqbin/p/10266783.html
一、CONCAT()函数
CONCAT()函数用于将多个字符串连接成一个字符串。
使用数据表Info作为示例,其中SELECT id,name FROM info LIMIT 1;的返回结果为
+----+--------+ | id | name | +----+--------+ | 1 | BioCyc | +----+--------+
1、语法及使用特点:
CONCAT(str1,str2,…)
返回结果为连接参数产生的字符串。如有任何一个参数为NULL ,则返回值为 NULL。可以有一个或多个参数。
2、使用示例:
SELECT CONCAT(id, ‘,’, name) AS con FROM info LIMIT 1;返回结果为
+----------+ | con | +----------+ | 1,BioCyc | +----------+
SELECT CONCAT(‘My’, NULL, ‘QL’);返回结果为
+--------------------------+
| CONCAT('My', NULL, 'QL') |
+--------------------------+
| NULL |
+--------------------------+
二、CONCAT_WS函数
如何指定参数之间的分隔符
使用函数CONCAT_WS()。使用语法为:CONCAT_WS(separator,str1,str2,…)
CONCAT_WS() 代表 CONCAT With Separator ,是CONCAT()的特殊形式。第一个参数是其它参数的分隔符。分隔符的位置放在要连接的两个字符串之间。分隔符可以是一个字符串,也可以是其它参数。如果分隔符为 NULL,则结果为 NULL。函数会忽略任何分隔符参数后的 NULL 值。但是CONCAT_WS()不会忽略任何空字符串。 (然而会忽略所有的 NULL)。
如SELECT CONCAT_WS(‘_’,id,name) AS con_ws FROM info LIMIT 1;返回结果为
+----------+ | con_ws | +----------+ | 1_BioCyc | +----------+
SELECT CONCAT_WS(‘,’,’First name’,NULL,’Last Name’);返回结果为
+----------------------------------------------+
| CONCAT_WS(',','First name',NULL,'Last Name') |
+----------------------------------------------+
| First name,Last Name |
+----------------------------------------------+
三、GROUP_CONCAT()函数
GROUP_CONCAT函数返回一个字符串结果,该结果由分组中的值连接组合而成。
使用表info作为示例,其中语句SELECT locus,id,journal FROM info WHERE locus IN(‘AB086827′,’AF040764’);的返回结果为

+----------+----+--------------------------+ | locus | id | journal | +----------+----+--------------------------+ | AB086827 | 1 | Unpublished | | AB086827 | 2 | Submitted (20-JUN-2002) | | AF040764 | 23 | Unpublished | | AF040764 | 24 | Submitted (31-DEC-1997) | +----------+----+--------------------------+
1、使用语法及特点:
GROUP_CONCAT([DISTINCT] expr [,expr ...]
[ORDER BY {unsigned_integer | col_name | formula} [ASC | DESC] [,col ...]]
[SEPARATOR str_val])
在 MySQL 中,你可以得到表达式结合体的连结值。通过使用 DISTINCT 可以排除重复值。如果希望对结果中的值进行排序,可以使用 ORDER BY 子句。
SEPARATOR 是一个字符串值,它被用于插入到结果值中。缺省为一个逗号 (“,”),可以通过指定 SEPARATOR “” 完全地移除这个分隔符。
可以通过变量 group_concat_max_len 设置一个最大的长度。在运行时执行的句法如下: SET [SESSION | GLOBAL] group_concat_max_len = unsigned_integer;
如果最大长度被设置,结果值被剪切到这个最大长度。如果分组的字符过长,可以对系统参数进行设置:SET @@global.group_concat_max_len=40000;
2、使用示例:
语句 SELECT locus,GROUP_CONCAT(id) FROM info WHERE locus IN(‘AB086827′,’AF040764’) GROUP BY locus; 的返回结果为
+----------+------------------+ | locus | GROUP_CONCAT(id) | +----------+------------------+ | AB086827 | 1,2 | | AF040764 | 23,24 | +----------+------------------+
语句 SELECT locus,GROUP_CONCAT(distinct id ORDER BY id DESC SEPARATOR ‘_’) FROM info WHERE locus IN(‘AB086827′,’AF040764’) GROUP BY locus;的返回结果为
+----------+----------------------------------------------------------+ | locus | GROUP_CONCAT(distinct id ORDER BY id DESC SEPARATOR '_') | +----------+----------------------------------------------------------+ | AB086827 | 2_1 | | AF040764 | 24_23 | +----------+----------------------------------------------------------+
语句SELECT locus,GROUP_CONCAT(concat_ws(‘, ‘,id,journal) ORDER BY id DESC SEPARATOR ‘. ‘) FROM info WHERE locus IN(‘AB086827′,’AF040764’) GROUP BY locus;的返回结果为
+----------+--------------------------------------------------------------------------+
| locus | GROUP_CONCAT(concat_ws(', ',id,journal) ORDER BY id DESC SEPARATOR '. ') |
+----------+--------------------------------------------------------------------------+
| AB086827 | 2, Submitted (20-JUN-2002). 1, Unpublished |
| AF040764 | 24, Submitted (31-DEC-1997) . 23, Unpublished |
四、CONCAT_WS(SEPARATOR ,collect_set(column))
===>GROUP_CONCAT()函数
在我们公司的hive(华为集群FunctionInsight)因为hive版本问题,并没有GROUP_CONCAT函数。只能用concat_ws和collect_set函数代替
但是排序性丧失。