flink部署
前置准备
:
1.CentOS7.5
2.java8
3.配置三台机器时间同步和免密登陆,关闭防火墙
| ip地址 | 主机名 |
|---|---|
| 192.168.10.128 | master |
| 192.168.10.129 | slave1 |
| 192.168.10.130 | Slave2 |
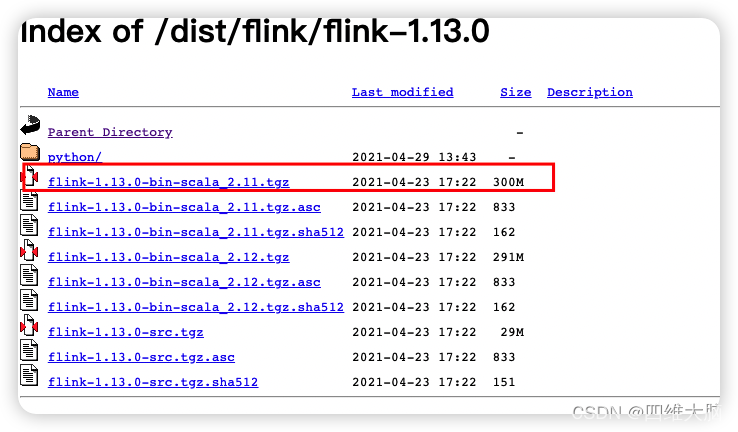
下载链接:https://flink.apache.org/zh/downloads.html#section-7
这里我选择的是1.13.0:https://archive.apache.org/dist/flink/flink-1.13.0/
组件:
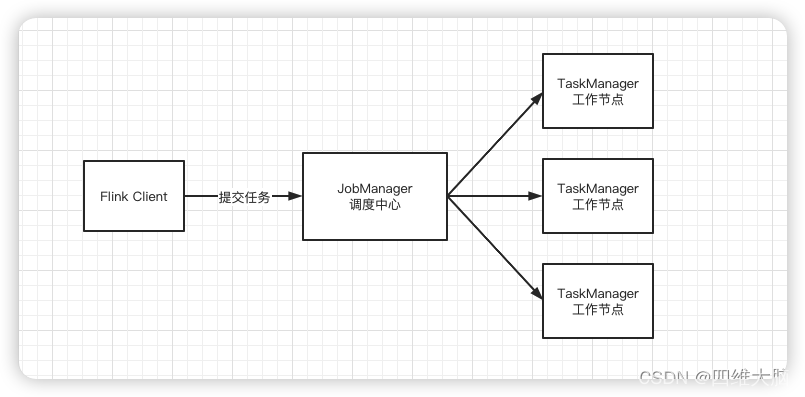
Flink中有几个关键性组件:客户端、调度中心(JobManager)、任务管理器(TaskManager)
我们通过客户端解析任务、然后提交到调度中心,调度中心分配任务到不同的工作节点运行。
单机模式
上传flink-1.13.0-bin-scala_2.12.tgz到/opt/software
解压(没有目录的话自行创建)
tar -zxvf flink-1.13.0-bin-scala_2.12.tgz -C /opt/module/
cd /opt/module/
mv flink-1.13.0 flink
启动
cd /opt/module/flink/bin
./start-cluster.sh
通过jps查看进程,包含StandaloneSessionClusterEntrypoint和TaskManagerRunner代表成功
10369 StandaloneSessionClusterEntrypoint
10680 TaskManagerRunner
flink提供了一个web页面,访问master:8081即可看到(要hosts文件配置了master对应的ip地址)
关闭集群
cd /opt/module/flink/bin
./stop-cluster.sh
会话模式(集群部署)
上传flink-1.13.0-bin-scala_2.12.tgz到/opt/software
master上解压(没有目录的话自行创建)
tar -zxvf flink-1.13.0-bin-scala_2.12.tgz -C /opt/module/
cd /opt/module/
mv flink-1.13.0 flink
修改配置,设置jobmanager
cd /opt/module/flink/conf
vim flink-conf.yaml
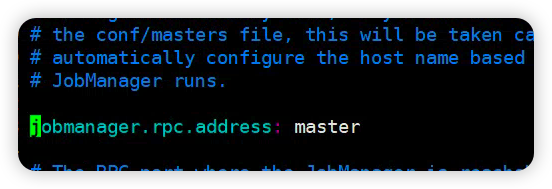
设置TaskManager 节点
vim workers
修改为
slave1
slave2
分发到slave1、slave2
scp -r /opt/module/flink/ root@slave1:/opt/module
scp -r /opt/module/flink/ root@slave2:/opt/module
只要在master启动
cd /opt/module/flink/bin
./start-cluster.sh
flink提供了一个web页面,访问master:8081即可看到(要hosts文件配置了master对应的ip地址)
yarn模式(推荐)
首先要确保有hadoop集群
| master | slave1 | slave2 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/
选择hadoop-3.1.3.tar.gz下载
上传至master节点
首先进行解压,然后分发到slave1和slave2,分别登陆到slave1,和slave2完成解压
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
scp hadoop-3.1.3.tar.gz root@slave1:/opt/software
scp hadoop-3.1.3.tar.gz root@slave2:/opt/software
配置环境变量
vim /root/.bash_profile
HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_CLASSPATH=`hadoop classpath`
重开shell窗口,查看hadoop版本
hadoop version

核心配置文件
cd /opt/module/hadoop-3.1.3/etc/hadoop/
vim core-site.xml
<!-- namenode地址端口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<!-- 数据存储目录-->
<property>
<name>hadoop.data.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
HDFS配置文件
vim hdfs-site.xml
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.data.dir}/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.data.dir}/data</value>
</property>
<!--主节点的元数据备份地址-->
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file://${hadoop.data.dir}/namesecondary</value>
</property>
<property>
<name>dfs.client.datanode-restart.timeout</name>
<value>30</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave2:9868</value>
</property>
YARN配置文件
vim yarn-site.xml
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>slave1</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- yarn容器允许分配的最大最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- yarn容器允许管理的物理内存大小 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 关闭yarn对虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
修改mapred-site.xml
vim mapred-site.xml
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
配置hadoop. jdk环境,不知道jdk在哪的可以echo $JAVA_HOME查看
vim /opt/module/hadoop-3.1.3/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_212
配置workers(不要有多余的空格)
vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
master
slave1
slave2
在启动之前需要修改一下启动文件,修改start-dfs.sh和stop-dfs.sh,在文件最开始加入下面四行
vim /opt/module/hadoop-3.1.3/sbin/start-dfs.sh
vim /opt/module/hadoop-3.1.3/sbin/stop-dfs.sh
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
修改start-dfs.sh和stop-dfs.sh,在文件最开始加入下面四行
vim /opt/module/hadoop-3.1.3/sbin/start-yarn.sh
vim /opt/module/hadoop-3.1.3/sbin/stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
同步sbin目录(启动命令),和etc/hadoop/目录下(配置文件),如果复制有问题自己手打
cd /opt/module/hadoop-3.1.3/etc/
scp -r hadoop/ root@slave1:/opt/module/hadoop-3.1.3/etc/
scp -r hadoop/ root@slave2:/opt/module/hadoop-3.1.3/etc/
cd /opt/module/hadoop-3.1.3
scp -r sbin/ root@slave1:/opt/module/hadoop-3.1.3/
scp -r sbin/ root@slave2:/opt/module/hadoop-3.1.3/
如果集群是第一次启动,需要在master节点格式化NameNode
cd /opt/module/hadoop-3.1.3/
bin/hdfs namenode -format
在master上执行
cd /opt/module/hadoop-3.1.3/
sbin/start-dfs.sh
在slave1上执行
cd /opt/module/hadoop-3.1.3/
sbin/start-yarn.sh
部署flink
解压flink,修改文件夹为flink-1.13.0-yarn
tar -zxvf flink-1.13.0-bin-scala_2.12.tgz -C /opt/module/
cd /opt/module
mv flink-1.13.0 flink-1.13.0-yarn
修改配置
vim flink-conf.yaml
jobmanager.memory.process.size: 1600m
taskmanager.memory.process.size: 1728m
taskmanager.numberOfTaskSlots: 8
parallelism.default: 1
启动,首先要保证hadoop集群启动成功
cd /opt/module/flink-1.13.0-yarn
bin/yarn-session.sh -nm test
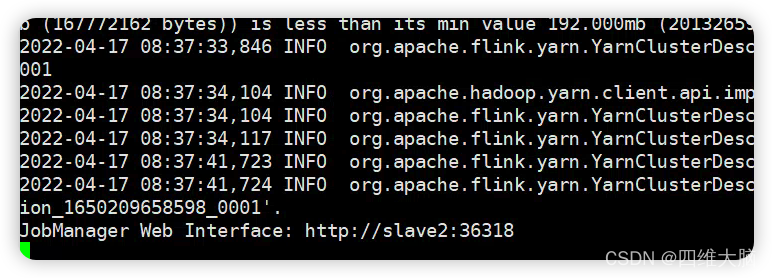
可以访问地址,看到客户端
最后说一句,尚硅谷yyds
https://www.bilibili.com/video/BV133411s7Sa?p=24&spm_id_from=pageDriver