本文分别用Numpy、Tensor、autograd来实现同一个机器学习任务,比较它们之间的异同及各自优缺点,从而加深大家对PyTorch的理解。
一、使用Numpy实现机器学习
首先,我们用最原始的Numpy实现有关回归的一个机器学习任务,不用PyTorch中的包或类。
主要
步骤
包括:
- 首先,给出一个数组x,然后基于表达式y=3×2+2,加上一些噪音数据到达另一组数据y。
- 然后,构建一个机器学习模型,学习表达式y=wx2+b的两个参数w、b。利用数组x,y的数据为训练数据。
- 最后,采用梯度梯度下降法,通过多次迭代,学习到w、b的值。
以下为
实战环节
的具体步骤:
1)
导入需要的库
。
import numpy as np
from matplotlib import pyplot as plt
%matplotlib inline
2)
生成输入数据x及目标数据y
。
设置随机数种子,即生成同一份数据,以便使用多种方法进行比较。
np.random.seed(666)
x = np.linspace(-1, 1, 100).reshape(100, 1)
y = 3 * np.power(x, 2) + 2 + 0.2 * np.random.rand(x.size).reshape(100, 1)
3)
查看x、y数据分布情况
。
# 绘图
plt.scatter(x,y)
plt.show()

4)
初始化权重参数
。
# 随机初始化参数
w = np.random.rand(1,1)
b = np.random.rand(1,1)
5)
训练模型
。
定义损失函数,假设批量大小为100:
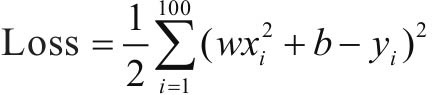
对损失函数求导:
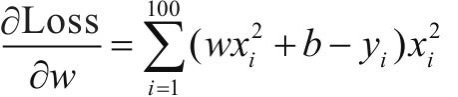
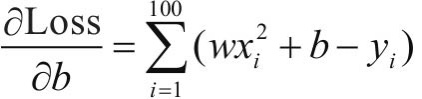
利用梯度下降法学习参数,学习率为lr。

用代码实现上面这些表达式:
lr = 0.001 # 学习率
for i in range(800):
# 前向传播
y_pred = np.power(x, 2) * w + b
# 定义损失函数
loss = 0.5 * (y_pred - y) ** 2
loss = loss.sum()
# 计算梯度
grad_w = np.sum((y_pred - y) * np.power(x, 2))
grad_b = np.sum(y_pred - y)
# 使用梯度下降法,是loss最小
w -= lr * grad_w
b -= lr * grad_b
6)
可视化结果
。
plt.plot(x, y_pred, 'r-', label='predict')
plt.scatter(x, y, color='blue', marker='o', label='true')
plt.xlim(-1, 1)
plt.ylim(2, 6)
plt.legend()
plt.show()
print(w, b)

[[2.99850472]] [[2.0989827]]从结果看来,学习效果还是还是比较理想的。
二、使用Tensor及Antograd实现机器学习
上节可以说是纯手工完成一个机器学习任务,数据用Numpy表示,梯度及学习是自己定义并构建学习模型。这种方法适合于比较简单的情况,如果稍微复杂一些,代码量将几何级增加。那是否有更方便的方法呢?
本节我们将使用PyTorch的一个自动求导的包——antograd,利用这个包及对应的Tensor,便可利用自动反向传播来求梯度,无须手工计算梯度。
以下为
实战环节
的具体步骤:
1)
导入需要的库
。
import torch as t
from matplotlib import pyplot as plt
%matplotlib inline
2)
生成训练数据,并可视化数据分布情况
。
# 随机种子
torch.manual_seed(666)
# 生成x坐标数据,x为tensor,需要把x的形状装换为100×1
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1)
# 生成y坐标数据,y为tensor,形状为100×1,另加上一些噪声
y = 3 * x.pow(2) + 2 + 0.2 * torch.rand(x.size())
# 绘图,把tensor数据转换为numpy数据
plt.scatter(x.numpy(), y.numpy())
plt.show()

3)
初始化权重参数
。
# 随机初始化参数,参数w,b为需要学习的,故需requires_grad=True
w = torch.randn(1, 1, dtype = torch.float, requires_grad=True)
b = torch.zeros(1, 1, dtype = torch.float, requires_grad=True)
4)
训练模型
。
lr = 0.001 # 学习率
for i in range(800):
# 前向传播
y_pred = x.pow(2).mm(w) + b
# 定义损失函数
loss = 0.5 * (y_pred - y) ** 2
loss = loss.sum()
# 自动计算梯度,梯度存放在grad属性中
loss.backward()
# 手动更新参数,需要用torch.no_grad(),使上下文环境中切断自动求导的计算
with torch.no_grad():
w -= lr * w.grad
b -= lr * b.grad
# 梯度清零
w.grad.zero_()
b.grad.zero_()
5)
可视化训练结果
。
plt.plot(x.numpy(), y_pred.detach().numpy(), 'r-', label='predict') # predict
plt.scatter(x.numpy(), y.numpy(), color='blue', marker='o', label='true') # true data
plt.xlim(-1, 1)
plt.ylim(2, 6)
plt.legend()
plt.show()
print(w, b)

tensor([[2.9578]], requires_grad=True) tensor([[2.0990]], requires_grad=True)这个结果与使用Numpy实现机器学习差不多。