
点击上方蓝字关注”程序员Bob”呀~

每个人的生命都是通向自我的征途,是对一条道路的尝试,是一条小径的悄然召唤。人们从来都无法以绝对的自我之相存在,每一个人都在努力变成绝对自我,有人迟钝,有人更洞明,但无一不是自己的方式。人人都背负着诞生之时的残余,背负着来自原初世界的黏液和蛋壳,直到生命的终点。
-《德米安 彷徨少年时》

之前了解过Requests库的用法,在Python爬虫中,用到
BeautifulSoup4
库的技术路线为Requests库+BeautifulSoup4库+re库,这里小编准备先聊聊Beautiful Soup4库。
至于为什么这个库要叫BeautifulSoup库(中文翻译为美丽的汤

),实在是令人百思不得其解,虽然小编知道它是由一个美丽的童话故事而来,但小编就是不说

。去官网就知道啦~(如下)
https://www.crummy.com/software/BeautifulSoup/
1.BeautifulSoup4库的功能
在官网对
BeautifulSoup4的简单介绍为:
Beautiful Soup提供了一些用于导航,搜索和修改解析树的简单方法和Pythonic习惯用法:用于剖析文档并提取所需内容的工具箱。编写应用程序不需要很多代码。
Beautiful Soup会自动将传入文档转换为Unicode,将传出文档转换为UTF-8。您不必考虑编码,除非文档未指定编码并且Beautiful Soup无法检测到编码。然后,您只需要指定原始编码即可。
Beautiful Soup位于流行的Python解析器(如lxml和html5lib)的顶部,使您可以尝试不同的解析策略或提高灵活性。
至于为什么后面有个4(代表版本号),因为BeautifulSoup3项目已停止开发,BeautifulSoup4也已被纳入到bs4里面了,所以在引用该库时需要使用:
from bs4 import BeautifulSoup
2.Beautiful Soup4库的安装
打开cmd命令行窗口,输入:pip install beautifulsoup4
编写一个小小的项目检查BeautifulSoup库是否安装成功:
import requestsfrom bs4 import BeautifulSoupr=requests.get(“https://python123.io/ws/demo.html”)print(r.text)demo=r.textsoup=BeautifulSoup(demo,”html.parser”)print(soup.prettify())
输出如下(截取部分):
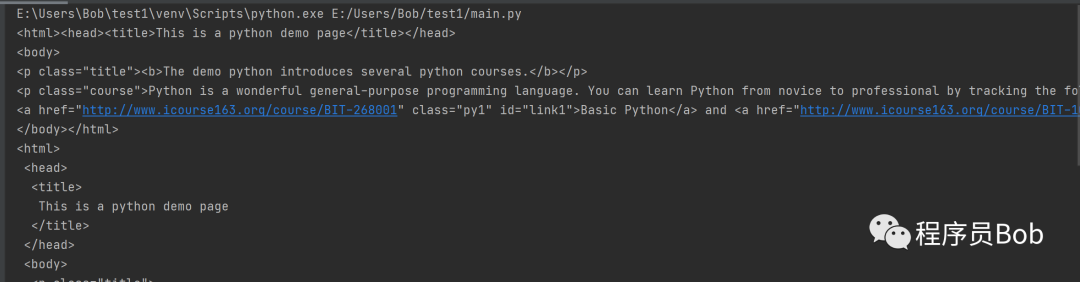
能正确输出即安装成功。
3.BeautifulSoup库的简单使用
有兴趣的小伙伴可以先试试运行下面的这段代码(建议输出语句逐条运行):
import requestsfrom bs4 import BeautifulSoupr=requests.get(“https://python123.io/ws/demo.html”)#print(r.text)demo=r.textsoup=BeautifulSoup(demo,”html.parser”)print(soup.prettify())print(soup.title)tag=soup.aprint(tag)print(soup.a.name)print(soup.a.parent.name)print(soup.a.parent.parent.name)print(tag.attrs)print(tag.attrs[‘class’])print(tag.attrs[‘href’])print(type(tag.attrs))print(type(tag))print(soup.a.string)print(soup.p.string)print(type(soup.p.string))
大家可以根据输出内容来判断其作用,实际上挺容易的。
首先是库的引用:
beautiful Soup 库:也叫beautifulsoup4或bs4
引用格式:from bs4 import BeautifulSoup#切记B和S要大写 ,
也可以直接用import bs4
引用之后的下面这条语句:
soup=BeautifulSoup(demo,”html.parser”)
其中,
html.parser
是一个html的解释器(解析前面demo里面的内容)。
那么什么是解释器呢?
百度:解释器,又译为直译器,是一种电脑程序,能够把高级编程语言一行一行直接转译运行。解释器不会一次把整个程序转译出来,只像一位“中间人”,每次运行程序时都要先转成另一种语言再作运行,因此解释器的程序运行速度比较缓慢。它每转译一行程序叙述就立刻运行,然后再转译下一行,再运行,如此不停地进行下去。
大概意思和编译器差不多,相关知识请自行百度。
关于BeautifulSoup库相关的解释器:
bs4的HTML解释器 BeautifulSoup(mk,’html.parser’) 需安装bs4库
lxml的HTML解释器 BeautifulSoup(mk,’lxml’) 安装命令:pip install lxml
lxml的XML解释器 BeautifulSoup(mk,’xml’) 安装命令:pip install lxml
html5lib的解释器 BeautifulSoup(mk,’html5lib’) 安装命令:pip install html5lib
其它语句就要知道BeautifulSoup类的基本元素:
Tag:标签,最基本的信息组织单元,分别用<>和>标明开头和结尾。
Name:标签的名字,
..
的名字是’p’,格式:.name。
Attributes:标签的属性,字典形式组织 格式::.attrs。
Navigable String:标签的非属性字符串,<>…>中字符串,格式:.string。
Comment:标签内字符串的注释部分,一种特殊的comment类型。
4.标签树的遍历:
标签树的下行遍历
相关属性及其说明(下同):
.content 子节点的列表,将所有儿子节点存入列表
.children 子节点的迭代类型,与.content类似,用于循环儿子结点
.descendants 子孙节点的迭代类型,包含所有子孙结点,用于循环遍历
实例:
import requestsfrom bs4 import BeautifulSoupr=requests.get(“https://python123.io/ws/demo.html”)#print(r.text)demo=r.textsoup=BeautifulSoup(demo,”html.parser”)print(soup.head)print(soup.head.contents)print(soup.body.contents)print(len(soup.body.contents))print(soup.body.contents[1])
标签树的下行遍历:
for child in soup.body.children:print(child)
标签树的上行遍历:
.parent :节点的父亲标签
.parents 节点先辈标签的迭代类型,用于循环遍历先辈节点
实例:
import requestsfrom bs4 import BeautifulSoupr=requests.get(“https://python123.io/ws/demo.html”)demo=r.textsoup=BeautifulSoup(demo,”html.parser”)for parent in soup.a.parents:if parent is None:print(parent)else:print(parent.name)
标签树的平行遍历:
.next.sibling 返回HTML文本顺序的下一个平行节点标签
.previous_sibling 返回按照HTML文本顺序的上一个平行节点
.next_siblings 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签
.previous_siblings 迭代类型,返回按照HTML文本顺序的前续所有平行节点标签
实例:
import requestsfrom bs4 import BeautifulSoupr=requests.get(“https://python123.io/ws/demo.html”)#print(r.text)demo=r.textsoup=BeautifulSoup(demo,”html.parser”)print(soup.a.next_sibling)#下一个标签print(soup.a.next_sibling.next_sibling)print(soup.a.previous_sibling)print(soup.a.previous_sibling.previous_sibling)print(soup.a.parent)#遍历后续节点for sibling in soup.a.next_siblings:print(sibling)#遍历前续节点for sibling in soup.a.previous_siblings:print(sibling)
To:bs4将任何读入的HTML文件或字符串都转换成utf-8编码。
Python爬虫系列,未完待续…

为你,千千万万遍.
往期推荐:
一键三连,就差你了
