定义
无序列表
:一种数据项按照相对位置存放的数据集 被称为“无序表unordered list”。
为了简单起见,我们假设列表不能包含重复项:例如,
整数 54,26,93,17,77 和 31 的集合可以表示考试分数的简单无序列表
。请注意,我们将它们用逗号分隔,这是列表结构的常用方式。如果用无序表表示,
这个列表显示 [54,26,93,17,77,31]
。
无序表list操作:
- List() 创建一个新的空列表。它不需要参数,并返回一个空列表。
- add(item) 向列表中添加一个新项。它需要 item 作为参数,并不返回任何内容。假定该 item 不在列表中。
- remove(item) 从列表中删除该项。它需要 item 作为参数并修改列表。假设项存在于列表中。
- search(item) 搜索列表中的项目。它需要 item 作为参数,并返回一个布尔值。
- isEmpty() 检查列表是否为空。它不需要参数,并返回布尔值。
- size()返回列表中的项数。它不需要参数,并返回一个整数。
- append(item) 将一个新项添加到列表末尾,使其成为集合中最后一项。它需要 item 作为参数,并不返回任何内容。假定该项不在列表中。
- index(item) 返回项在列表中的位置。它需要 item 作为参数并返回索引。假定该项在列表中。
- insert(pos,item) 在位置 pos 处向列表中添加一个新项。它需要 item作为参数并不返回任何内容。假设该项不在列表中,并且有足够的现有项使其有 pos 的位置。
- pop() 删除并返回列表中的最后一个项。假设该列表至少有一个项。
- pop(pos) 删除并返回位置 pos 处的项。它需要 pos 作为参数并返回项。假定该项在列表中。
链表实现无序表
链接表
:不需要数据项依次存放在连续的存储空间内。
数据存放位置没有规则,但是数据项间建立链接指向,就可以保持其前后相对位置
节点node类
链表实现的最基本元素,由列表项(item,数据字段)和对应下一节点的引用组成。其包含访问、修改数据,以及访问下一个引用的等操作。
实现代码:
class Node:
def __init__(self,initdata):
self.data = initdata
self.next = None
def getData(self):
return self.data
def getNext(self):
return self.next
def setData(self,newdata):
self.data = newdata
def setNext(self,newnext):
self.next = newnext
#创建一个Node对象
temp=Node(93)

Unordered list 类
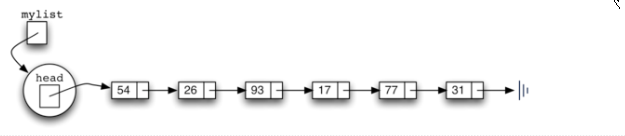
无序列表将从一组节点构建,每个节点通过显式引用链接到下一个节点。只要我们知道在哪里找到第一个节点(包含第一个项),之后的每个项可以通过连续跟随下一个链接找到。考虑到这一点,
UnorderedList 类必须保持对第一个节点的引用
,
设立一个属性head,保存对第一个节点的引用,并判断是否为空
class UnorderedList:
def __init__(self):
self.head = None
def isEmpty(self):
return self.head == None
Underedlist其他操作python实现:
def isEmpty(self):
return self.head == None
def add(self,item):
temp = Node(item)
#更改新节点的下一个引用以引用旧链表的第一个节点
temp.setNext(self.head)
#赋值语句设置列表的头
self.head = temp
#访问和赋值的顺序不能颠倒,因为head是链表节点唯一的外部引用,颠倒将导致所有原始节点丢失并且不能再被访问
def size(self):
current = self.head
count = 0
while current != None:
count = count + 1
current = current.getNext()
return count
def search(self,item):
current = self.head
found = False
while current != None and not found:
if current.getData() == item:
found = True
else:
current = current.getNext()
return found
def remove(self,item):
current = self.head
previous = None
found = False
while not found:
if current.getData() == item:
found = True
#previous 必须先将一个节点移动到 current 的位置。此时,才可以移动current
else:
previous = current
current = current.getNext()
#如果要删除的项目恰好是链表中的第一个项,链表的 head 需要改变
if previous == None:
self.head = current.getNext()
else:
previous.setNext(current.getNext())
操作过程解析:
链表的次序很重要!
链表的查找都是从表头head开始,沿着next逐个查找,因此,添加数据项最快的位置是表头,链表的首位置。


remove方法需要两个步骤
- 搜索
-
删除,
但是current实际指向的是目标节点的引用,直接删除会删除前一个节点,因此引入previous这个外部引用。


链表的算法分析
对于链表的复杂度分析,主要看相应的方法是否涉及到链表的遍历。

注意:链表实现的list,跟python内置的列表数据类型不同,其时间复杂度也有所差异,主要是因为
python内置的列表数据类型是基于顺序存储来实现的,并进行了优化
参考来源:陈斌,《数据结构与算法python版》
https://www.icourse163.org/learn/PKU-1206307812?tid=1450242471#/learn/content?type=detail&id=1214420511&cid=1218119335