C++ 中的 vector 长度是如何动态增长的
推荐我的个人博客:
blog.wuzhenyu.com.cn
下面这篇文章的前半部分,是一篇译文,原文地址
1
:
http://www.drdobbs.com/c-made-easier-how-vectors-grow/184401375
c++ 标准库函数默认情况下提供了合理的性能,但是,如何做到“合理”的呢,read on next.
介绍
假如我们需要从一个文件中读取一组 double 类型的值,并保存在一个数据结构中,我们可以通过以下方式很快速的实现:
vector<double> values;
double x;
while (cin >> x)
values.push_back(x);
当循环结束时,values 将保存所有这些值。我们可以通过变量 i 和 values[i] 来快速访问这些值。
直观来说,标准库函数中的 vector 类就像是一个内置数组:我们可以把他想象成一组保存数据的连续的内存块,能够通过 values[i] 来访问。确实,C++ 标准并没有明确规定 vector 的元素必须占用连续的内存块,但是 2000 年 10 月的标准委员会 (the standard commitee) 会议通过,认为这是一项疏忽,并把这个要求加入到了它的技术勘误表中 (Technical Corrigendum)。这一迟来的决定,并没有造成多大的问题,因为使用 vector 实现的这些代码中,都是按照这个约定来工作的。
如果 vector 的元素是保存在连续的内存中的,那么就可以很容易的理解 vector 的元素访问为什么如此高效了 – 这就像是数组一样,能够对数据元素随机存取 (it simply uses the same mechanism as the built-in arrays use.)。但是,不容易理解的是, vector 是如何高效的组织元素自己动态增长的呢,因为保存在连续的内存中,不可避免的需要将数据从一个内存块复制到另一个内存块。现在处理器在处理连续内存块的复制方面已经可以做到很高效了,但是这些拷贝是不被释放的,会占用大量的内存。因此,需要思考,标准库函数中 vector 的增长,在没有占用大量时间和空间的情况下,是如何实现的。
下面来讨论一种简单、高效的策略来管理这种动态内存的增长。
大小和容量 (size and capacity)
想要弄清楚 vector 是如何工作的,首先就要清楚 vector 并不仅仅是一个连续的内存块,每一个 vector 都有两个相关两的内存块。一个是大小块,保存有 vector 元素个数,另一个为容量,是 vector 的整个内存大小,能够保存 vector 的所有元素。比如 v 是一个 vector 类的对象,v.size() 和 v.capacity() 将返回 v 的大小和容量。可以想成下面这种结构:
---------------------------------
| elements | available space |
--- size ---
---------- capacity -------------
在 vector 的末尾额外使用一个内存的意义,是在使用
push_back
加入元素的时候,可以不需要再去申请内存。如果这块内存刚好紧邻 vector 的内存,那么直接将这块内存直接加入到 vector 上就能实现内存增长。但是这种情况极少,大多数情况下,都需要去申请一块更大的新内存,然后将所有的元素都拷贝到新内存块中,然后释放掉原有的内存块。
内存再分配会经过一下四步:
-
申请足够大的内存保存所有的元素
-
将原有的元素拷贝到新内存中
-
销毁原内存块中的元素
- 将原内存块释放,归还给操作系统
如果有 n 个元素,那么上述操作的时间复杂度为 O(n),每次增加一个元素都需要执行一次。2 和 3 步骤将耗费主要的时间。因此,这种方法,当我们为 vector 在申请 n 大小的时候需要耗费 O(n) 的时间。
现在采用一种折中的方法。当我们再分配的时候,我们额外申请很多空间,这样,在下一次添加元素的时候,就不需要频繁的进行再分配,这样能节约很多时间。但是这种方式的代价就是需要浪费一些空间。另一方面,我们可以只申请一点额外的空间,这样做可以节约空间,只需要花时间在额外的再分配上。换句话说,我们是通过空间换取了时间。
再分配策略 (Reallocation Strategy)
举一个极端点的例子,假设我们需要往一个 vector 对象中添加元素,我们每一次都需要扩大 vector 的容量,即申请多一个的空间存储新增的元素。虽然这么做,能很好的节省空间,需要多大就申请多大,但是如果需要添加 n 个元素,那么我们需要重新申请 n 次空间,并且每次都需要将原来的元素拷贝到新申请的内存块中,时间为 O(n)。也就是说,如果我们需要在一个空的 vector 中添加 k 个元素,总的时间为
O(1 + 2 + 3 + ... + k) = O(k(1+k)/2)
即时间复杂度为 O(k
2
),这种策略效率是很差的。(That’s terrible!)
现在,我们换一种策略,假设我们每次扩大 vector 的容量的时候,不是每次只增加一,而是增加一个恒定的大小 C。通过这个增长因子 C,能明显较少重申请的次数,这当然是一个进步,但是效率能有多大提升呢?
上面这中策略在我们每次添加 C 个元素的时候,都需要扩大 vector 的容量,冲申请一次。假设我们需要添加 K*C 个元素,那么第一次重申请需要拷贝 C 个元素,第二次需要拷贝 2C 个元素……,消耗的总时间仍然是二次方。
二次方的时间复杂度的策略,还有很大的可优化的空间,即使使用高性能的处理器和大内存也不能解决问题。
上述策略分析得知,为 vector 再分配内存,扩大容量时,每次申请仅仅是扩大一个固定的大小,时间复杂度达到二次方。相反,额外申请的容量必须随着 vector 容量的增长而增长。那么,如果我们每次为 vector 重新申请内存时,额外申请的空间是之前的 2 倍大小的话,可以显著的降低时间复杂度,为 O(n)。
当我们为 vector 重新申请内存并向 vector 添加元素时,我们将 vector 想成一下这种结构:
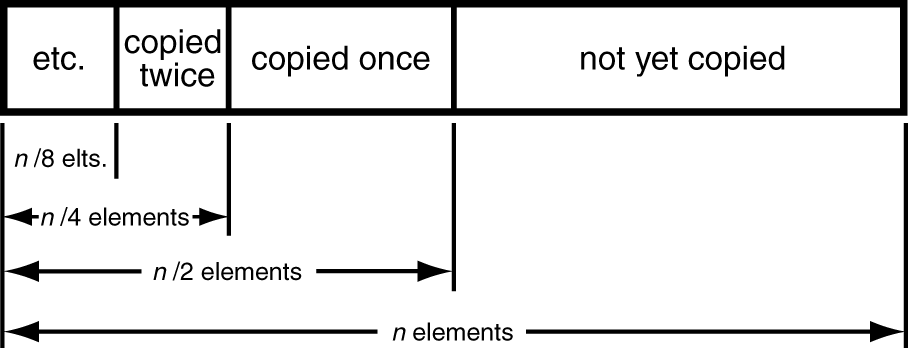
最后一次重新分配内存之后,有一半的空间可以添加新元素,所以这部分元素不需要拷贝,但是原先的那
n/2
个元素需要进行拷贝到新申请的内存中;同理,上一次重分配时,有
n/4
的元素需要拷贝,以此一次类推,获得如下公式
total = (n/2)*1 + (n/2^2)*2 + (n/2^3)*3 + ... + (n/2^k)*k
这就是时间复杂度的计算公式,结果为
total = 2n - (n/2^k)(2+k)
时间复杂度达到了 O(n)。
讨论 discussion
C++ 标准并没有强制要求 vector 类必须按照特定的方式管理内存,标准要求的是创建一个 n 个元素的 vector ,重复调用
push_back
添加元素的时间控制在 O(n) 内。我们讨论的重分配的策略恰恰是一种最直观的能够满足这一条件的方式。
既然 vector 的性能这么好,那我们当然可以使用如下的循环进行编码
vector<double> values;
double x;
while (cin >> x) {
values.push_back (x)
}
这种再分配的策略申请的额外内存会随着 vector 容量 (capacity) 增长而增长,它比每次只固定增加某一大小的方法性能要高,但是,如果你能预测或者已经知道你需要保存的元素的数量,直接申请一块能够保存所有元素的内存块存储这些元素,岂不更好吗?
一条华丽的分割线
上面的译文,讲述了 c++ 中 vector 的动态增长因子为 2,以及为 2 的好处,但是并没有说明为什么是 2
What is the ideal growth rate for a dynamically allocated array
动态数组的增长因素依赖很多元素,包括时间与空间的权衡以及用于内存分配的算法。关于最佳增长因子,展开过很多次讨论,包括推荐使用黄金比例来进行。(The Golden Ratio – Phi, 1.618)。以下是一些比较流行的语言中的增长因子
2
:
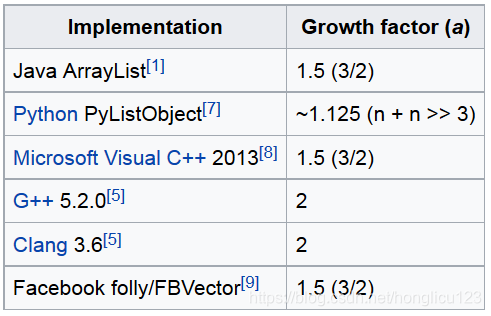
在有些讨论中
3
,
认为增长因子 1.5 要优于 2
,首先我们分析一下增长因子为 2 的情况:
1、 假如现在申请了一个 16B 的内存空间
2、 当我们需要更多内存的时候,我们申请了 32B 的内存空间,释放掉之前的 16B
3、 当我们在需要更多内存的时候,我们需要申请 64B 的内存空间,释放掉之前的 32B 的空间,此时一共释放了 16B+32B=48B 的空间
4、 当我们继续需要更大的空间的时候,我们需要申请 128B 的空间,释放的总空间大小为 112B
5、 依次类推
根据以上思路,每次内存重申请都是原来内存的两倍大小,根据申请的内存大小和释放的内存大小可知,指数增长总是更快,也就是说释放的总的内存大小总是小于下一次需要申请的内存大小,这样造成的情况就是,每次都不能对之前的内存复用
4
(上面的文章中已经说过了,一般申请都是连续的内存)。
如果增长因子为 1.5 的话,分析如下:
1、 假如申请了 16B 的内存空间
2、 再次申请内存需要申请 24B 的空间,释放掉之前的 16B 的空间
3、 需要更多内存时,需要申请 36B 的空间,释放空间为 40B
4、 需要更多内存时,需要申请 54B 的空间,释放空间为 76B
5、 需要更多内存时,需要申请 81B 的空间,释放空间为 130B
6、 需要更多内存时,需要申请 122B 的空间,此时,可以使用前面释放的 130B 的空间,这样就能充分利用到内存。
有些人认为,如果增长因子是 1.5,那么在计算申请内存的时候,需要先转换成浮点数,然后计算后,在转换成整数,这样大大增加了计算量。
但是,
1.5 倍,等于是 old * 3/2,/2 可以使用位运算 >>1 来实现。所以,并不需要非要进行浮点运算转换。
那么,下面我们思考一下,如果我们增长因子为 x,最开始申请的内存空间大小为 T。下一次需要申请的内存为
T*x
,释放空间为 T;当需要更多内存时,再次申请内存为
T*x^2
,释放空间为
T + T*x
;……
我们的目标就是后面申请新内存时,能够重用到之前释放的那些内存(假设他们是相邻的),也就是说新申请的内存不超过之前释放的内存之和,得到如下等式:
T*x^n <= T + T*x + T*x^2 + ... + T*x^(n-2)
等式两边消除 T 所得:
x^n <= 1 + x + x^2 + ... + x^(n-2)
通常,我们说第 n 次申请内存,期望是第 n 次申请内存,能够使用到之前释放的内存,也就是释放的内存总和不小于第 n 次申请的内存大小。
比如,根据上面的等式,当我们想要在第三步就能达到这种预期,即 n = 3
x^3 <= 1 + x
等式的解为
0 < x < 2
,精确一点就是
0 < x < 1.3
,当 n 为其他值时如下
n maximum-x (roughly)
3 1.3
4 1.4
5 1.53
6 1.57
7 1.59
22 1.61
增长因子都比 2 小。
参考文献: